欢迎进入Flask大型教程项目!¶
翻译者注:本系列的原文名为:The Flask Mega-Tutorial ,作者是 Miguel Grinberg 。
本系列是作者平时使用 Flask 微框架编写应用的经验之谈,这里是这一系列中所有已经发布的文章的索引。
Hello World¶
作者背景¶
作者是一个使用多种语言开发复杂程序并且拥有十多年经验的软件工程师。作者第一次学习 Python 是在为一个 C++ 库创建绑定的时候。
除了 Python,作者曾经用 PHP, Ruby, Smalltalk 甚至 C++ 写过 web 应用。在所有这些中,Python/Flask 组合是作者认为最为自由的一种。
应用程序简介¶
作为本教程的一部分–我要开发的应用程序是一个极具特色的微博服务器,我称之为 microblog 。
我会随着应用程序的不断地进展将涉及到如下这些主题:
- 用户管理,包括管理登录,会话,用户角色,权限以及用户头像。
- 数据库管理,包括迁移处理。
- Web 表单支持,包括对各个字段的验证。
- 分页处理。
- 全文搜索。
- 用户邮件提醒。
- HTML 模板。
- 支持多国语言。
- 缓存以及其它性能优化技术。
- 开发以及生产服务器的调试技巧。
- 在生产服务器上安装。
我希望这个应用程序将能够成为编写其它类型的 web 应用程序的一个样板,当它完成的时候。
要求¶
如果你有一台能够运行 Python 的机器,可能你将会很轻松。该教程中的应用程序能够完美地运行在 Windows, OS X 以及 Linux 上。除非另有说明,本系列的文章中提供的代码已经在 Python 2.7 和 3.4 上测试过。
本教程假定你很熟悉操作系统的终端窗口(命令提示符为 Windows 用户),清楚基本命令行文件管理功能。如果你还不熟悉这些的话,我强烈建议你先学习使用命令行,比如如何创建文件夹等,接着再继续。
最后,你应该还能够很舒服地(熟练地)编写 Python 代码。强烈推荐熟悉 Python 的 Python 模块和包 。
安装 Flask¶
好的,让我们开始吧!
现在我们必须开始安装 Flask 以及一些我们会用到的扩展。我首选的方式就是创建一个 虚拟环境 ,这个环境能够安装所有的东西,而你的主 Python 不会受到影响。另外一个好处就是这种方式不需要你拥有 root 权限。
因此,打开一个终端窗口,选择一个你想要放置应用程序的位置以及创建一个包含它的新的文件夹。让我们把这个应用程序的文件夹称为 microblog 。
如果你正在使用 Python 3.4,先进入到 microblog 目录中接着使用如下的命令创建一个虚拟环境:
$ python -m venv flask
需要注意地是在某些系统中你可能要使用 python3 来代替 python。上面的命令行在 flask 文件夹中创建一个完整的 Python 环境。
如果你使用 Python 3.4 以下的版本(包括 python 2.7),你需要在创建虚拟环境之前下载以及安装 virtualenv.py 。如果你在使用 Mac OS X,请使用下面的命令行安装:
$ sudo easy_install virtualenv
如果你使用 Linux,你需要获取一个包。例如,如果你使用 Ubuntu:
$ sudo apt-get install python-virtualenv
Windows 用户们在安装 virtualenv 上有些麻烦,因此如果你想省事的话,请直接安装 Python 3.4。在 Windows 上安装 virtualenv 最简单地方式就是先安装 pip,安装方式在 这里 <https://pip.pypa.io/en/latest/installing.html>。一旦安装好了 pip 的话,下面的命令可以安装 virtualenv:
$ pip install virtualenv
为了创建一个虚拟环境,请输入如下的命令行
$ virtualenv flask
上面的命令行在 flask 文件夹中创建一个完整的 Python 环境。
虚拟环境是能够激活以及停用的,如果需要的话,一个激活的环境可以把它的 bin 文件夹加入到系统路径。我个人是不喜欢这种特色,所以我从来不激活任何环境相反我会直接输入我想要调用的解释器的路径。
如果你是在 Linux, OS X 或者 Cygwin 上,通过一个接一个输入如下的命令行来安装 flask 以及扩展:
$ flask/bin/pip install flask
$ flask/bin/pip install flask-login
$ flask/bin/pip install flask-openid
$ flask/bin/pip install flask-mail
$ flask/bin/pip install flask-sqlalchemy
$ flask/bin/pip install sqlalchemy-migrate
$ flask/bin/pip install flask-whooshalchemy
$ flask/bin/pip install flask-wtf
$ flask/bin/pip install flask-babel
$ flask/bin/pip install guess_language
$ flask/bin/pip install flipflop
$ flask/bin/pip install coverage
如果是在 Windows 上的话,命令行有些不同
$ flask\Scripts\pip install flask
$ flask\Scripts\pip install flask-login
$ flask\Scripts\pip install flask-openid
$ flask\Scripts\pip install flask-mail
$ flask\Scripts\pip install flask-sqlalchemy
$ flask\Scripts\pip install sqlalchemy-migrate
$ flask\Scripts\pip install flask-whooshalchemy
$ flask\Scripts\pip install flask-wtf
$ flask\Scripts\pip install flask-babel
$ flask\Scripts\pip install guess_language
$ flask\Scripts\pip install flipflop
$ flask\Scripts\pip install coverage
这些命令行将会下载以及安装我们将会在我们的应用程序中使用的所有的包。
在 Flask 中的 “Hello, World”¶
现在在你的 microblog 文件夹中下有一个 flask 子文件夹,这里有 Python 解释器以及 Flask 框架以及我们将要在这个应用程序中使用的扩展。 是时候去编写我们第一个 web 应用程序!
在 cd 到 microblog 文件夹后,我们开始为应用程序创建基本的文件结构:
mkdir app
mkdir app/static
mkdir app/templates
mkdir tmp
我们的应用程序包是放置于 app 文件夹中。子文件夹 static 是我们存放静态文件像图片,JS文件以及样式文件。子文件夹 templates 显然是存放模板文件。
让我们开始为我们的 app 包(文件 app/__init__.py )创建一个简单的初始化脚本:
from flask import Flask
app = Flask(__name__)
from app import views
上面的脚本简单地创建应用对象,接着导入视图模块,该模块我们暂未编写。
视图是响应来自网页浏览器的请求的处理器。在 Flask 中,视图是编写成 Python 函数。每一个视图函数是映射到一个或多个请求的 URL。
让我们编写第一个视图函数(文件 app/views.py ):
from app import app
@app.route('/')
@app.route('/index')
def index():
return "Hello, World!"
其实这个视图是非常简单,它只是返回一个字符串,在客户端的网页浏览器上显示。两个 route 装饰器创建了从网址 / 以及 /index 到这个函数的映射。
能够完整工作的 Web 应用程序的最后一步是创建一个脚本,启动我们的应用程序的开发 Web 服务器。让我们称这个脚本为 run.py,并把它置于根目录:
#!flask/bin/python
from app import app
app.run(debug = True)
这个脚本简单地从我们的 app 包中导入 app 变量并且调用它的 run 方法来启动服务器。请记住 app 变量中含有我们在之前创建的 Flask 实例。
要启动应用程序,您只需运行此脚本(run.py)。在OS X,Linux 和 Cygwin 上,你必须明确这是一个可执行文件,然后你可以运行它:
chmod a+x run.py
然后脚本可以简单地按如下方式执行:
./run.py
在 Windows 上过程可能有些不同。不再需要指明文件是否可执行。相反你必须运行该脚本作为 Python 解释器的一个参数:
flask/Scripts/python run.py
在服务器初始化后,它将会监听 5000 端口等待着连接。现在打开你的网页浏览器输入如下 URL:
http://localhost:5000
另外你也可以使用这个 URL:
http://localhost:5000/index
你看清楚了路由映射是如何工作的吗?第一个 URL 映射到 /,而第二个 URL 映射到 /index。这两个路由都关联到我们的视图函数,因此它们的作用是一样的。如果你输入其它的网址,你将会获得一个错误,因为只有这两个 URL 映射到视图函数。
你可以通过 Ctrl-C 来终止服务器。到这里,我将会结束这一章的内容。对于不想输入代码的用户,你可以到这里下载代码:microblog-0.1.zip。
下一步?¶
下一章我们将会小小修改下我们的应用,使用 HTML 模板。我希望在下一章再见到大家!
模板¶
回顾¶
如果你依照 Hello World 这一章的话,你应当有一个完全工作的简单的 web 应用程序,它有着如下的文件结构:
microblog\
flask\
<virtual environment files>
app\
static\
templates\
__init__.py
views.py
tmp\
run.py
你可以执行 run.py 来运行应用程序,接着在你的网页浏览器上打开 http://localhost:5000 网址。
在 Python 中生成 HTML 并不好玩,实际上是相当繁琐的,因为你必须自行做好 HTML 转义以保持应用程序的安全。由于这个原因,Flask 自动为你配置好 Jinja2 模版。我们将会在这一章中介绍一些模板基本概念以及基本用法。
我们接下来讲述的正是我们上一章离开的地方,所以你可能要确保应用程序 microblog 正确地安装和工作。
为什么我们需要模板¶
让我们来考虑下我们该如何扩充我们这个小的应用程序。
我们希望我们的微博应用程序的主页上有一个欢迎登录用户的标题,这是这种类型的应用程序的一个“标配”。忽略本应用程序暂未有用户的事实,我会在后面的章节引入用户的概念。
输出一个漂亮的大标题的一个容易的选择就是改变我们的视图功能,输出 HTML,也许像这个样子:
from app import app
@app.route('/')
@app.route('/index')
def index():
user = { 'nickname': 'Miguel' } # fake user
return '''
<html>
<head>
<title>Home Page</title>
</head>
<body>
<h1>Hello, ''' + user['nickname'] + '''</h1>
</body>
</html>
'''
运行看看网页浏览器上的显示情况。
我们暂时还不支持用户,所以暂时使用占位符的用户对象,有时也被称为假冒或模仿的对象。这样让我们可以集中关注应用程序的某一方面,而不用花心思在暂未完成的部分上。
我希望你同意我的说法,上面的解决方案是非常难看!如果我们需要返回一个含有大量动态内容的大型以及复杂的 HTML 页面的话,代码将会有多么复杂啊!如果你需要改变你的网站布局,在一个大的应用程序,该应用程序有几十个视图,每一个直接返回HTML?这显然不是一个可扩展的选择。
模板从天而降¶
如果你能够保持你的应用程序与网页的布局或者界面逻辑上是分开的,这样不是显得更加容易组织?难道你不觉得是这样吗?你甚至可以聘请一个网页设计师来设计一个杀手级的网页而你专注于 Python 编码。模板可以帮助实现这种分离。
让我们编写第一个我们的模板(文件 app/templates/index.html):
<html>
<head>
<title>{{title}} - microblog</title>
</head>
<body>
<h1>Hello, {{user.nickname}}!</h1>
</body>
</html>
正如你在上面看到,我们只是写了一个大部分标准的HTML页面,唯一的区别是有一些动态内容的在 {{ ... }} 中。
现在看看怎样在我们的视图函数(文件 app/views.py)中使用这些模板:
from flask import render_template
from app import app
@app.route('/')
@app.route('/index')
def index():
user = { 'nickname': 'Miguel' } # fake user
return render_template("index.html",
title = 'Home',
user = user)
试着运行下应用程序看看模板是如何工作的。一旦在你的网页浏览器上呈现该网页,你可以浏览下 HTML 源代码,与原始的模板内容对比下差别。
为了渲染模板,我们必须从 Flask 框架中导入一个名为 render_template 的新函数。此函数需要传入模板名以及一些模板变量列表,返回一个所有变量被替换的渲染的模板。
在内部,render_template 调用了 Jinja2 模板引擎,Jinja2 模板引擎是 Flask 框架的一部分。Jinja2 会把模板参数提供的相应的值替换了 {{...}} 块。
模板中控制语句¶
Jinja2 模板同样支持控制语句,像在 {%...%} 块中。让我们在我们的模板中添加一个 if 声明(文件 app/templates/index.html):
<html>
<head>
{% if title %}
<title>{{title}} - microblog</title>
{% else %}
<title>Welcome to microblog</title>
{% endif %}
</head>
<body>
<h1>Hello, {{user.nickname}}!</h1>
</body>
</html>
现在我们的模板变得更加智能了。如果视图函数忘记输入页面标题的参数,不会触发异常反而会出现我们自己提供的标题。放心地去掉视图函数中 render_template 的调用中的 title 参数,看看 if 语句是如何工作的!
模板中的循环语句¶
在我们 microblog 应用程序中,登录的用户想要在首页展示他的或者她的联系人列表中用户最近的文章,因此让我们看看如何才能做到。
首先我们先创建一些用户以及他们的文章用来展示(文件 app/views.py):
def index():
user = { 'nickname': 'Miguel' } # fake user
posts = [ # fake array of posts
{
'author': { 'nickname': 'John' },
'body': 'Beautiful day in Portland!'
},
{
'author': { 'nickname': 'Susan' },
'body': 'The Avengers movie was so cool!'
}
]
return render_template("index.html",
title = 'Home',
user = user,
posts = posts)
为了表示用户的文章,我们使用了列表,其中每一个元素包含 author 和 body 字段。当我们使用真正的数据库的时候,我们会保留这些字段的名称,因此我们在设计以及测试模板的时候尽管使用的是假冒的对象,但不必担心迁移到数据库上更新模板。
在模板这一方面,我们必须解决一个新问题。列表中可能有许多元素,多少篇文章被展示将取决于视图函数。模板不会假设有多少文章,因此它必须准备渲染视图传送的文章数量。
因此让我们来看看怎么使用 for 来做到这一点(文件 app/templates/index.html):
<html>
<head>
{% if title %}
<title>{{title}} - microblog</title>
{% else %}
<title>microblog</title>
{% endif %}
</head>
<body>
<h1>Hi, {{user.nickname}}!</h1>
{% for post in posts %}
<p>{{post.author.nickname}} says: <b>{{post.body}}</b></p>
{% endfor %}
</body>
</html>
简单吧?试试吧,确保给予足够的文章列表。
模板继承¶
在这一章结束前我们将讨论最后一个话题。
在我们的 microblog 应用程序中,在页面的顶部需要一个导航栏。在导航栏里面有编辑账号,登出等等的链接。
我们可以在 index.html 模板中添加一个导航栏,但是随着应用的扩展,越来越多的模板需要这个导航栏,我们需要在每一个模板中复制这个导航栏。然而你必须要保证每一个导航栏都要同步,如果你有大量的模板,这需要花费很大的力气。
相反,我们可以利用 Jinja2 的模板继承的特点,这允许我们把所有模板公共的部分移除出页面的布局,接着把它们放在一个基础模板中,所有使用它的模板可以导入该基础模板。
所以让我们定义一个基础模板,该模板包含导航栏以及上面谈论的标题(文件 app/templates/base.html):
<html>
<head>
{% if title %}
<title>{{title}} - microblog</title>
{% else %}
<title>microblog</title>
{% endif %}
</head>
<body>
<div>Microblog: <a href="/index">Home</a></div>
<hr>
{% block content %}{% endblock %}
</body>
</html>
在这个模板中,我们使用 block 控制语句来定义派生模板可以插入的地方。块被赋予唯一的名字。
接着现在剩下的就是修改我们的 index.html 模板继承自 base.html (文件 app/templates/index.html):
{% extends "base.html" %}
{% block content %}
<h1>Hi, {{user.nickname}}!</h1>
{% for post in posts %}
<div><p>{{post.author.nickname}} says: <b>{{post.body}}</b></p></div>
{% endfor %}
{% endblock %}
结束语¶
如果你想要节省时间的话,你可以下载 microblog-0.2.zip。
但是请注意的是 zip 文件已经不包含 flask 虚拟环境了,如果你想要运行应用程序的话,请按照前一章的步骤自己创建它。
在下一章中,我们将会讨论到表单。我希望能在下一章继续见到各位!
web 表单¶
回顾¶
在上一章节中,我们定义了一个简单的模板,使用占位符来虚拟了暂未实现的部分,比如用户以及文章等。
在本章我们将要讲述应用程序的特性之一–表单,我们将会详细讨论如何使用 web 表单。
Web 表单是在任何一个 web 应用程序中最基本的一部分。我们将使用表单允许用户写文章,以及登录到应用程序中。
我们接下来讲述的正是我们上一章离开的地方,所以你可能要确保应用程序 microblog 正确地安装和工作。
配置¶
为了能够处理 web 表单,我们将使用 Flask-WTF ,该扩展封装了 WTForms 并且恰当地集成进 Flask 中。
许多 Flask 扩展需要大量的配置,因此我们将要在 microblog 文件夹的根目录下创建一个配置文件以至于容易被编辑。这就是我们将要开始的(文件 config.py):
CSRF_ENABLED = True
SECRET_KEY = 'you-will-never-guess'
十分简单吧,我们的 Flaks-WTF 扩展只需要两个配置。 CSRF_ENABLED 配置是为了激活 跨站点请求伪造 保护。在大多数情况下,你需要激活该配置使得你的应用程序更安全些。
SECRET_KEY 配置仅仅当 CSRF 激活的时候才需要,它是用来建立一个加密的令牌,用于验证一个表单。当你编写自己的应用程序的时候,请务必设置很难被猜测到密钥。
既然我们有了配置文件,我们需要告诉 Flask 去读取以及使用它。我们可以在 Flask 应用程序对象被创建后去做,方式如下(文件 app/__init__.py):
from flask import Flask
app = Flask(__name__)
app.config.from_object('config')
from app import views
用户登录表单¶
在 Flask-WTF 中,表单是表示成对象,Form 类的子类。一个表单子类简单地把表单的域定义成类的变量。
我们将要创建一个登录表单,用户用于认证系统。在我们应用程序中支持的登录机制不是标准的用户名/密码类型,我们将使用 OpenID。OpenIDs 的好处就是认证是由 OpenID 的提供者完成的,因此我们不需要验证密码,这会让我们的网站对用户而言更加安全。
OpenID 登录仅仅需要一个字符串,被称为 OpenID。我们将在表单上提供一个 ‘remember me’ 的选择框,以至于用户可以选择在他们的网页浏览器上种植 cookie ,当他们再次访问的时候,浏览器能够记住他们的登录。
所以让我们编写第一个表单(文件 app/forms.py):
from flask.ext.wtf import Form
from wtforms import StringField, BooleanField
from wtforms.validators import DataRequired
class LoginForm(Form):
openid = StringField('openid', validators=[DataRequired()])
remember_me = BooleanField('remember_me', default=False)
我相信这个类不言而明。我们导入 Form 类,接着导入两个我们需要的字段类,TextField 和 BooleanField。
DataRequired 验证器只是简单地检查相应域提交的数据是否是空。在 Flask-WTF 中有许多的验证器,我们将会在以后看到它们。
表单模板¶
我们同样需要一个包含生成表单的 HTML 的模板。好消息是我们刚刚创建的 LoginForm 类知道如何呈现为 HTML 表单字段,所以我们只需要集中精力在布局上。这里就是我们登录的模板(文件 app/templates/login.html):
<!-- extend from base layout -->
{% extends "base.html" %}
{% block content %}
<h1>Sign In</h1>
<form action="" method="post" name="login">
{{form.hidden_tag()}}
<p>
Please enter your OpenID:<br>
{{form.openid(size=80)}}<br>
</p>
<p>{{form.remember_me}} Remember Me</p>
<p><input type="submit" value="Sign In"></p>
</form>
{% endblock %}
请注意,此模板中,我们重用了 base.html 模板通过 extends 模板继承声明语句。实际上,我们将在所有我们的模板中做到这一点,以确保所有网页的布局一致性。
在我们的模板与常规的 HTML 表单之间存在一些有意思的不同处。模板期望一个实例化自我们刚才创建地表单类的表单对象储存成一个模板参数,称为 form。当我们编写渲染这个模板的视图函数的时候,我们将会特别注意传送这个模板参数到模板中。
form.hidden_tag() 模板参数将被替换为一个隐藏字段,用来是实现在配置中激活的 CSRF 保护。如果你已经激活了 CSRF,这个字段需要出现在你所有的表单中。
我们表单中实际的字段也将会被表单对象渲染,你只必须在字段应该被插入的地方指明一个 {{form.field_name}} 模板参数。某些字段是可以带参数的。在我们的例子中,我们要求表单生成一个 80 个字符宽度的 openid 字段。
因为我们并没有在表单中定义提交按钮,我们必须按照普通的字段来定义。提交字段实际并不携带数据因此没有必要在表单类中定义。
表单视图¶
在我们看到我们表单前的最后一步就是编写渲染模板的视图函数的代码。
实际上这是十分简单因为我们只需要把一个表单对象传入模板中。这就是我们新的视图函数(文件 app/views.py):
from flask import render_template, flash, redirect
from app import app
from .forms import LoginForm
# index view function suppressed for brevity
@app.route('/login', methods = ['GET', 'POST'])
def login():
form = LoginForm()
return render_template('login.html',
title = 'Sign In',
form = form)
所以基本上,我们已经导入 LoginForm 类,从这个类实例化一个对象,接着把它传入到模板中。这就是我们渲染表单所有要做的。
让我们先忽略 flash 以及 redirect 的导入。我们会在后面介绍。
这里唯一的新的知识点就是路由装饰器的 methods 参数。参数告诉 Flask 这个视图函数接受 GET 和 POST 请求。如果不带参数的话,视图只接受 GET 请求。
这个时候你可以尝试运行应用程序,在浏览器上看看表单。在你运行应用程序后,你需要在浏览器上打开 http://localhost:5000/login 。
我们暂时还没有编写接收数据的代码,因此此时按提交按钮不会有任何作用。
接收表单数据¶
Flask-WTF 使得工作变得简单的另外一点就是处理提交的数据。这里是我们登录视图函数更新的版本,它验证并且存储表单数据 (文件 app/views.py):
@app.route('/login', methods = ['GET', 'POST'])
def login():
form = LoginForm()
if form.validate_on_submit():
flash('Login requested for OpenID="' + form.openid.data + '", remember_me=' + str(form.remember_me.data))
return redirect('/index')
return render_template('login.html',
title = 'Sign In',
form = form)
validate_on_submit 方法做了所有表单处理工作。当表单正在展示给用户的时候调用它,它会返回 False.
如果 validate_on_submit 在表单提交请求中被调用,它将会收集所有的数据,对字段进行验证,如果所有的事情都通过的话,它将会返回 True,表示数据都是合法的。这就是说明数据是安全的,并且被应用程序给接受了。
如果至少一个字段验证失败的话,它将会返回 False,接着表单会重新呈现给用户,这也将给用户一次机会去修改错误。我们将会看到当验证失败后如何显示错误信息。
当 validate_on_submit 返回 True,我们的登录视图函数调用了两个新的函数,导入自 Flask。flash 函数是一种快速的方式下呈现给用户的页面上显示一个消息。在我们的例子中,我将会使用它来调试,因为我们目前还不具备用户登录的必备的基础设施,相反我们将会用它来显示提交的数据。flash 函数在生产服务器上也是十分有作用的,用来提供反馈给用户有关的行动。
闪现的消息将不会自动地出现在我们的页面上,我们的模板需要加入展示消息的内容。我们将添加这些消息到我们的基础模板中,这样所有的模板都能继承这个函数。这是更新后的基础模板(文件 app/templates/base.html):
<html>
<head>
{% if title %}
<title>{{title}} - microblog</title>
{% else %}
<title>microblog</title>
{% endif %}
</head>
<body>
<div>Microblog: <a href="/index">Home</a></div>
<hr>
{% with messages = get_flashed_messages() %}
{% if messages %}
<ul>
{% for message in messages %}
<li>{{ message }} </li>
{% endfor %}
</ul>
{% endif %}
{% endwith %}
{% block content %}{% endblock %}
</body>
</html>
显示闪现消息的技术希望是不言自明的。
在我们登录视图这里使用的其它新的函数就是 redirect。这个函数告诉网页浏览器引导到一个不同的页面而不是请求的页面。在我们的视图函数中我们用它重定向到前面已经完成的首页上。要注意地是,闪现消息将会显示即使视图函数是以重定向结束。
是到了启动应用程序的时候,测试下表单是如何工作的。确保您尝试提交表单的时候,OpenID 字段为空,看看 Required 验证器是如何中断提交的过程。
加强字段验证¶
现阶段的应用程序,如果表单提交不合理的数据将不会被接受。相反,会返回表单让用户提交合法的数据。这确实是我们想要的。
然后,好像我们缺少了一个提示用户表单哪里出错了。幸运的是,Flask-WTF 也能够轻易地做到这一点。
当字段验证失败的时候, Flask-WTF 会向表单对象中添加描述性的错误信息。这些信息是可以在模板中使用的,因此我们只需要增加一些逻辑来获取它。
这就是我们含有字段验证信息的登录模板(文件 app/templates/login.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<h1>Sign In</h1>
<form action="" method="post" name="login">
{{ form.hidden_tag() }}
<p>
Please enter your OpenID:<br>
{{ form.openid(size=80) }}<br>
{% for error in form.openid.errors %}
<span style="color: red;">[{{ error }}]</span>
{% endfor %}<br>
</p>
<p>{{ form.remember_me }} Remember Me</p>
<p><input type="submit" value="Sign In"></p>
</form>
{% endblock %}
唯一的变化就是我们增加了一个循环获取验证 openid 字段的信息。通常情况下,任何需要验证的字段都会把错误信息放入 form.field_name.errors 下。在我们的例子中,我们使用 form.openid.errors 。我们以红色的字体颜色显示这些错误信息以引起用户的注意。
处理 OpenIDs¶
事实上,很多用户并不知道他们已经有一些 OpenIDs。一些大的互联网服务提供商支持 OpenID 认证自己的会员这并不是众所周知的。比如,如果你有一个 Google 的账号,你也就有了一个它们的 OpenID。
为了让用户更方便地使用这些常用的 OpenID 登录到我们的网站,我们把它们的链接转成短名称,用户不必手动地输入这些 OpenID。
我首先开始定义一个 OpenID 提供者的列表。我们可以把它们写入我们的配置文件中(文件 config ):
CSRF_ENABLED = True
SECRET_KEY = 'you-will-never-guess'
OPENID_PROVIDERS = [
{ 'name': 'Google', 'url': 'https://www.google.com/accounts/o8/id' },
{ 'name': 'Yahoo', 'url': 'https://me.yahoo.com' },
{ 'name': 'AOL', 'url': 'http://openid.aol.com/<username>' },
{ 'name': 'Flickr', 'url': 'http://www.flickr.com/<username>' },
{ 'name': 'MyOpenID', 'url': 'https://www.myopenid.com' }]
现在让我们看看如何在我们登录视图函数中使用它们:
@app.route('/login', methods = ['GET', 'POST'])
def login():
form = LoginForm()
if form.validate_on_submit():
flash('Login requested for OpenID="' + form.openid.data + '", remember_me=' + str(form.remember_me.data))
return redirect('/index')
return render_template('login.html',
title = 'Sign In',
form = form,
providers = app.config['OPENID_PROVIDERS'])
我们从配置中获取 OPENID_PROVIDERS,接着把它作为 render_template 中一个参数传入模板中。
我敢确信你们已经猜到了,我们还需要多做一步来达到目的。我们现在就来说明如何在登录模板中渲染这些提供商的链接(文件 app/templates/login.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<script type="text/javascript">
function set_openid(openid, pr)
{
u = openid.search('<username>')
if (u != -1) {
// openid requires username
user = prompt('Enter your ' + pr + ' username:')
openid = openid.substr(0, u) + user
}
form = document.forms['login'];
form.elements['openid'].value = openid
}
</script>
<h1>Sign In</h1>
<form action="" method="post" name="login">
{{ form.hidden_tag() }}
<p>
Please enter your OpenID, or select one of the providers below:<br>
{{ form.openid(size=80) }}
{% for error in form.openid.errors %}
<span style="color: red;">[{{error}}]</span>
{% endfor %}<br>
|{% for pr in providers %}
<a href="javascript:set_openid('{{ pr.url }}', '{{ pr.name }}');">{{ pr.name }}</a> |
{% endfor %}
</p>
<p>{{ form.remember_me }} Remember Me</p>
<p><input type="submit" value="Sign In"></p>
</form>
{% endblock %}
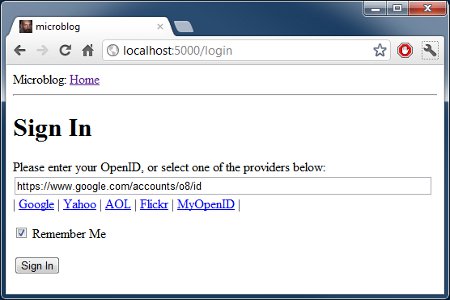
模板变得跟刚才不一样了。一些 OpenIDs 含有用户名,因此对于这些用户,我们必须利用 javascript 的魔力提示用户输入用户名并且组成 OpenIDs。当用户点击一个 OpenIDs 提供商的链接并且(可选)输入用户名,该提供商相应的 OpenID 就被写入到文本域中。
下面就是点击 Google OpenID 链接后,我们登录界面的一个截图:
结束语¶
尽管我们在登录表单上已经取得了很多进展,我们实际上没有做任何用户登录到我们的系统,到目前为止我们所做的是登录过程的 GUI 方面。这是因为在做实际登录之前,我们需要有一个数据库,那里可以记录我们的用户。
在下一章中,我们会得到我们的数据库并且运行它,接着我们将完成我们的登录系统。敬请关注后续文章。
如果你想要节省时间的话,你可以下载 microblog-0.3.zip。
但是请注意的是 zip 文件已经不包含 flask 虚拟环境了,如果你想要运行应用程序的话,请按照第一章的步骤自己创建它。
数据库¶
回顾¶
在前面的章节中,我们已经创建了登录表单,完成了提交以及验证。在这篇文章中,我们要创建我们的数据库,并设置它,这样我们就可以保存我们的用户。
我们接下来讲述的正是我们上一章离开的地方,所以你可能要确保应用程序 microblog 正确地安装和工作。
从命令行中运行 Python 脚本¶
在这一章中我们会写一些脚本用来简化数据库的管理。在我们开始编写脚本之前,先来温习下 Python 脚本如何在命令行中执行。
如果你使用 Linux 或者 OS X 系统的话,脚本必须给予一定的权限,像这样:
chmod a+x script.py
脚本中有一个 shebang ,它指明应该使用的解释器。一个脚本如果被赋予了执行权限并且有一个 shebang 行能够被简单地像这样执行:
./script.py <arguments>
在 Windows 上,上面的操作是没有作用的,相反你必须提供脚本作为选择的 Python 解释器的一个参数:
flask\Scripts\python script.py <arguments>
为了避免键入 Python 解释器的路径,你可以把 microblog/flask/Scripts 加入到系统路径中,但是务必让它在你的 Python 解释器之前。
从现在起,在本教程中的 Linux / OS X 的语法将用于缩写。如果你是在 Windows 上,记得适当的语法转换。
Flask 中的数据库¶
我们将使用 Flask-SQLAlchemy 扩展来管理我们应用程序的数据。这个扩展封装了 SQLAlchemy 项目,这是一个 对象关系映射器 或者 ORM。
ORMs 允许数据库应用程序与对象一起工作,而不是表以及 SQL。执行在对象的操作会被 ORM 翻译成数据库命令。这就意味着我们将不需要学习 SQL,我们将让 Flask-SQLAlchemy 代替 SQL。
迁移¶
我见过的大多数数据库教程会涉及到创建和使用一个数据库,但没有充分讲述随着应用程序扩大更新数据库的问题。通常情况下,每次你需要进行更新,你最终不得不删除旧的数据库和创建一个新的数据库,并且失去了所有的数据。如果数据不能容易地被重新创建,你可能会被迫自己编写导出和导入脚本。
幸运地,我们还有一个更好的选择。
我们将使用 SQLAlchemy-migrate 来跟踪数据库的更新。它只是在开始建立数据库的时候多花费些工作,这只是很小的代价,以后就再不用担心人工数据迁移了。
配置¶
针对我们小型的应用,我们将采用 sqlite 数据库。sqlite 数据库是小型应用的最方便的选择,每一个数据库都是存储在单个文件里。
我们有许多新的配置项需要添加到配置文件中(文件 config.py):
import os
basedir = os.path.abspath(os.path.dirname(__file__))
SQLALCHEMY_DATABASE_URI = 'sqlite:///' + os.path.join(basedir, 'app.db')
SQLALCHEMY_MIGRATE_REPO = os.path.join(basedir, 'db_repository')
SQLALCHEMY_DATABASE_URI 是 Flask-SQLAlchemy 扩展需要的。这是我们数据库文件的路径。
SQLALCHEMY_MIGRATE_REPO 是文件夹,我们将会把 SQLAlchemy-migrate 数据文件存储在这里。
最后,当我们初始化应用程序的时候,我们也必须初始化数据库。这是我们更新后的初始化文件(文件 app/__init__.py):
from flask import Flask
from flask.ext.sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config.from_object('config')
db = SQLAlchemy(app)
from app import views, models
注意我们在初始化脚本中的两个改变。创建了一个 db 对象,这是我们的数据库,接着导入一个新的模块,叫做 models。接下来我们将编写这个模块。
数据库模型¶
我们存储在数据库中数据将会以类的集合来表示,我们称之为数据库模型。ORM 层需要做的翻译就是将从这些类创建的对象映射到适合的数据库表的行。
让我们创建一个表示用户的模型。使用 WWW SQL Designer 工具,我制作如下的图来表示我们用户的表:
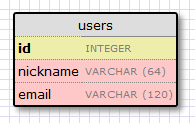
id 字段通常会在所有模型中,并且用于作为主键。在数据库的每一个用户会被赋予一个不同的 id 值,存储在这个字段中。幸好这是自动完成的,我们仅仅需要的是提供 id 这个字段。
nickname 以及 email 字段是被定义成字符串,并且指定了最大的长度以便数据库可以优化空间占用。
现在我们已经决定用户表的样子,剩下的工作就是把它转换成代码(文件 app/models.py):
from app import db
class User(db.Model):
id = db.Column(db.Integer, primary_key = True)
nickname = db.Column(db.String(64), index = True, unique = True)
email = db.Column(db.String(120), index = True, unique = True)
def __repr__(self):
return '<User %r>' % (self.nickname)
我们刚刚创建的 User 类包含一些字段,这些字段被定义成类的变量。字段是被作为 db.Column 类的实例创建的,db.Column 把字段的类型作为参数,并且还有一些其它可选的参数,比如表明字段是否唯一。
__repr__ 方法告诉 Python 如何打印这个类的对象。我们将用它来调试。
创建数据库¶
配置以及模型都已经到位了,是时候准备创建数据库文件。SQLAlchemy-migrate 包自带命令行和 APIs,这些 APIs 以一种将来允许容易升级的方式来创建数据库。我发现命令行使用起来比较别扭,因此我们自己编写一些 Python 脚本来调用迁移的 APIs。
这是创建数据库的脚本(文件 db_create.py):
#!flask/bin/python
from migrate.versioning import api
from config import SQLALCHEMY_DATABASE_URI
from config import SQLALCHEMY_MIGRATE_REPO
from app import db
import os.path
db.create_all()
if not os.path.exists(SQLALCHEMY_MIGRATE_REPO):
api.create(SQLALCHEMY_MIGRATE_REPO, 'database repository')
api.version_control(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO)
else:
api.version_control(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO, api.version(SQLALCHEMY_MIGRATE_REPO))
为了创建数据库,你需要运行这个脚本(记得如果在 Windows 上命令有些不同):
./db_create.py
在运行上述命令之后你会发现一个新的 app.db 文件。这是一个空的 sqlite 数据库,创建一开始就支持迁移。同样你还将有一个 db_repository 文件夹,里面还有一些文件,这是 SQLAlchemy-migrate 存储它的数据文件的地方。请注意,我们不会再生的存储库,如果它已经存在。这将使我们重新创建数据库,同时保留现有的存储库,如果我们需要。
第一次迁移¶
现在,我们已经定义了我们的模型,我们可以将其合并到我们的数据库中。我们会把应用程序数据库的结构任何的改变看做成一次迁移,因此这是我们第一次迁移,我们将从一个空数据库迁移到一个能存储用户的数据库上。
为了实现迁移,我们需要编写一小段 Python 代码(文件 db_migrate.py):
#!flask/bin/python
import imp
from migrate.versioning import api
from app import db
from config import SQLALCHEMY_DATABASE_URI
from config import SQLALCHEMY_MIGRATE_REPO
migration = SQLALCHEMY_MIGRATE_REPO + '/versions/%03d_migration.py' % (api.db_version(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO) + 1)
tmp_module = imp.new_module('old_model')
old_model = api.create_model(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO)
exec old_model in tmp_module.__dict__
script = api.make_update_script_for_model(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO, tmp_module.meta, db.metadata)
open(migration, "wt").write(script)
api.upgrade(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO)
print 'New migration saved as ' + migration
print 'Current database version: ' + str(api.db_version(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO))
脚本看起来很复杂,其实际上做的并不多。SQLAlchemy-migrate 迁移的方式就是比较数据库(在本例中从 app.db 中获取)与我们模型的结构(从文件 app/models.py 获取)。两者间的不同将会被记录成一个迁移脚本存放在迁移仓库中。迁移脚本知道如何去迁移或撤销它,所以它始终是可能用于升级或降级一个数据库。
然而在使用上面的脚本自动地完成迁移的时候也不是没有问题的,我见过有时候它很难识别新老格式的变化。为了让 SQLAlchemy-migrate 容易地识别出变化,我绝不会重命名存在的字段,我仅限于增加或者删除模型或者字段,或者改变已存在字段的类型。当然我一直会检查生成的迁移脚本,确保它是正确。
毋庸置疑你不应该在没有备份下去尝试迁移数据库。当然也不能在生产环境下直接运行迁移脚本,必须在开发环境下确保迁移运转正常。
因此让我们继续进行,记录下迁移:
./db_migrate.py
脚本的输出如下:
New migration saved as db_repository/versions/001_migration.py
Current database version: 1
脚本会打印出迁移脚本存储在哪里,也会打印出目前数据库版本。空数据库的版本是0,在我们迁移到包含用户的数据库后,版本为1.
数据库升级和回退¶
到现在你可能想知道为什么完成记录数据库迁移的这项令人麻烦的事情是这么重要。
假设你有一个应用程序在开发机器上,同时有一个拷贝部署在到线上的生产机器上。在下一个版本中,你的数据模型有一个变化,比如新增了一个表。如果没有迁移脚本,你可能必须要琢磨着如何修改数据库格式在开发和生产机器上,这会花费很大的工作。
如果有数据库迁移的支持,当你准备发布新版的时候,你只需要录制一个新的迁移,拷贝迁移脚本到生产服务器上接着运行脚本,所有事情就完成了。数据库升级也只需要一点 Python 脚本(文件 db_upgrade.py):
#!flask/bin/python
from migrate.versioning import api
from config import SQLALCHEMY_DATABASE_URI
from config import SQLALCHEMY_MIGRATE_REPO
api.upgrade(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO)
print 'Current database version: ' + str(api.db_version(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO))
当你运行上述脚本的时候,数据库将会升级到最新版本。
通常情况下,没有必要把数据库降低到旧版本,但是,SQLAlchemy-migrate 支持这么做(文件 db_downgrade.py):
#!flask/bin/python
from migrate.versioning import api
from config import SQLALCHEMY_DATABASE_URI
from config import SQLALCHEMY_MIGRATE_REPO
v = api.db_version(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO)
api.downgrade(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO, v - 1)
print 'Current database version: ' + str(api.db_version(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO))
这个脚本会回退数据库一个版本。你可以运行多次来回退多个版本。
数据库关系¶
关系型数据可以很好的存储数据项之间的关系。考虑一个用户写了一篇 blog 的例子。在 users 表中有一条用户的数据,在 posts 表中有一条 blog 数据。记录是谁写了这篇 blog 的最有效的方式就是连接这两条相关的数据项。
一旦在用户和文章(post)的联系被建立,有两种类型的查询是我们可能需要使用的。最常用的查询就是查询 blog 的作者。复杂一点的查询就是一个用户的所有的 blog。Flask-SQLAlchemy 将会帮助我们完成这两种查询。
让我们扩展数据库以便存储 blog。为此我们回到数据库设计工具并且创建一个 posts 表。
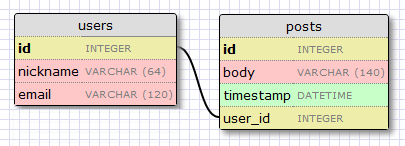
我们的 posts 表中有必须得 id 字段,以及 blog 的 body 以及一个 timestamp。这里没有多少新东西。只是对 user_id 字段需要解释下。
我们说过想要连接用户和他们写的 blog。方式就是通过在 posts 增加一个字段,这个字段包含了编写 blog 的用户的 id。这个 id 称为一个外键。我们的数据库设计工具把外键显示成一个连线,这根连线连接于 users 表中的 id 与 posts 表中的 user_id。这种关系称为一对多,一个用户编写多篇 blog。
让我们修改模型以反映这些变化(app/models.py):
from app import db
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
nickname = db.Column(db.String(64), index=True, unique=True)
email = db.Column(db.String(120), index=True, unique=True)
posts = db.relationship('Post', backref='author', lazy='dynamic')
def __repr__(self):
return '<User %r>' % (self.nickname)
class Post(db.Model):
id = db.Column(db.Integer, primary_key = True)
body = db.Column(db.String(140))
timestamp = db.Column(db.DateTime)
user_id = db.Column(db.Integer, db.ForeignKey('user.id'))
def __repr__(self):
return '<Post %r>' % (self.body)
我们添加了一个 Post 类,这是用来表示用户编写的 blog。在 Post 类中的 user_id 字段初始化成外键,因此 Flask-SQLAlchemy 知道这个字段是连接到用户上。
值得注意的是我们已经在 User 类中添加一个新的字段称为 posts,它是被构建成一个 db.relationship 字段。这并不是一个实际的数据库字段,因此是不会出现在上面的图中。对于一个一对多的关系,db.relationship 字段通常是定义在“一”这一边。在这种关系下,我们得到一个 user.posts 成员,它给出一个用户所有的 blog。不用担心很多细节不知道什么意思,以后我们会不断地看到例子。
首先还是来运行迁移脚本:
./db_migrate.py
输出:
New migration saved as db_repository/versions/002_migration.py
Current database version: 2
编程时间¶
我们花了很多时间定义我们的数据库,但是我们仍没有看到它是如何工作的。因为我们的应用程序中还没有关于数据库的代码,让我们先在 Python 解释器上试用下我们全新的数据库。
让我们先启动 Python。在 Linux 或者 OS X 上:
flask/bin/python
或者在 Windows 上:
flask\Scripts\python
一旦启动 Python,在 Python 提示符中输入如下语句:
>>> from app import db, models
>>>
这将会把我们的数据库和模型载入内存中。
首先创建一个新用户:
>>> u = models.User(nickname='john', email='[email protected]')
>>> db.session.add(u)
>>> db.session.commit()
>>>
在会话的上下文中完成对数据库的更改。多个的更改可以在一个会话中累积,当所有的更改已经提交,你可以发出一个 db.session.commit(),这能原子地写入更改。如果在会话中出现错误的时候, db.session.rollback() 可以是数据库回到会话开始的状态。如果即没有 commit 也没有 rollback 发生,系统默认情况下会回滚会话。会话保证数据库将永远保持一致的状态。
让我们添加另一个用户:
>>> u = models.User(nickname='susan', email='[email protected]')
>>> db.session.add(u)
>>> db.session.commit()
>>>
现在我们可以查询用户:
>>> users = models.User.query.all()
>>> print users
[<User u'john'>, <User u'susan'>]
>>> for u in users:
... print u.id,u.nickname
...
1 john
2 susan
>>>
对于查询用户,我们使用 query 成员,这是对所有模型类都是可用的。
这是另外一种查询。如果你知道用户的 id ,我们能够找到这个用户的数据像下面这样:
>>> u = models.User.query.get(1)
>>> print u
<User u'john'>
>>>
现在让我们提交一篇 blog:
>>> import datetime
>>> u = models.User.query.get(1)
>>> p = models.Post(body='my first post!', timestamp=datetime.datetime.utcnow(), author=u)
>>> db.session.add(p)
>>> db.session.commit()
这里我们设置我们的 timestamp 为 UTC 时区。所有存储在数据库的时间戳都会是 UTC。我们有来自世界上不同地方的用户因此需要有个统一的时间单位。在后面的教程中会以当地的时间呈现这些时间在用户面前。
你可能注意到了我们并没有设置 user_id 字段。相反我们在 author 字段上存储了一个 User 对象。ORM 层将会知道怎么完成 user_id 字段。
让我们多做一些查询:
# get all posts from a user
>>> u = models.User.query.get(1)
>>> print u
<User u'john'>
>>> posts = u.posts.all()
>>> print posts
[<Post u'my first post!'>]
# obtain author of each post
>>> for p in posts:
... print p.id,p.author.nickname,p.body
...
1 john my first post!
# a user that has no posts
>>> u = models.User.query.get(2)
>>> print u
<User u'susan'>
>>> print u.posts.all()
[]
# get all users in reverse alphabetical order
>>> print models.User.query.order_by('nickname desc').all()
[<User u'susan'>, <User u'john'>]
>>>
Flask-SQLAlchemy 文档可能会提供更多有帮助的信息。
在结束之前,需要清除一下刚才创建的数据,以便在下一章中会有一个干净的数据库:
>>> users = models.User.query.all()
>>> for u in users:
... db.session.delete(u)
...
>>> posts = models.Post.query.all()
>>> for p in posts:
... db.session.delete(p)
...
>>> db.session.commit()
>>>
结束语¶
这是一个漫长的教程。我们已经学会了使用数据库的基本知识,但我们还没有纳入到我们的应用程序的数据库。在下一章中,我们将会把我们所学到的所有关于数据库的知识用于实践。
如果你想要节省时间的话,你可以下载 microblog-0.4.zip。
我希望能在下一章继续见到各位!
用户登录¶
回顾¶
在上一章中,我们已经创建了数据库以及学会了使用它来存储用户以及 blog,但是我们并没有把它融入我们的应用程序中。在两章以前,我们已经看到如何创建表单并且留下了一个完全实现的登录表单。
在本章中我们将会建立 web 表单和数据库的联系,并且编写我们的登录系统。在本章结尾的时候,我们这个小型的应用程序将能够注册新用户并且能够登入和登出。
我们接下来讲述的正是我们上一章离开的地方,所以你可能要确保应用程序 microblog 正确地安装和工作。
配置¶
像以前章节一样,我们从配置将会使用到的 Flask 扩展开始入手。对于登录系统,我们将会使用到两个扩展,Flask-Login 和 Flask-OpenID。配置情况如下(文件 app/__init__.py):
import os
from flask.ext.login import LoginManager
from flask.ext.openid import OpenID
from config import basedir
lm = LoginManager()
lm.init_app(app)
oid = OpenID(app, os.path.join(basedir, 'tmp'))
Flask-OpenID 扩展需要一个存储文件的临时文件夹的路径。对此,我们提供了一个 tmp 文件夹的路径。
重构用户模型¶
Flask-Login 扩展需要在我们的 User 类中实现一些特定的方法。但是类如何去实现这些方法却没有什么要求。
下面就是我们为 Flask-Login 实现的 User 类(文件 app/models.py):
class User(db.Model):
id = db.Column(db.Integer, primary_key = True)
nickname = db.Column(db.String(64), unique = True)
email = db.Column(db.String(120), unique = True)
posts = db.relationship('Post', backref = 'author', lazy = 'dynamic')
def is_authenticated(self):
return True
def is_active(self):
return True
def is_anonymous(self):
return False
def get_id(self):
try:
return unicode(self.id) # python 2
except NameError:
return str(self.id) # python 3
def __repr__(self):
return '<User %r>' % (self.nickname)
is_authenticated 方法有一个具有迷惑性的名称。一般而言,这个方法应该只返回 True,除非表示用户的对象因为某些原因不允许被认证。
is_active 方法应该返回 True,除非是用户是无效的,比如因为他们的账号是被禁止。
is_anonymous 方法应该返回 True,除非是伪造的用户不允许登录系统。
最后,get_id 方法应该返回一个用户唯一的标识符,以 unicode 格式。我们使用数据库生成的唯一的 id。需要注意地是在 Python 2 和 3 之间由于 unicode 处理的方式的不同我们提供了相应的方式。
user_loader 回调¶
现在我们已经准备好用 Flask-Login 和 Flask-OpenID 扩展来开始实现登录系统。
首先,我们必须编写一个函数用于从数据库加载用户。这个函数将会被 Flask-Login 使用(文件 app/views.py):
@lm.user_loader
def load_user(id):
return User.query.get(int(id))
请注意在 Flask-Login 中的用户 ids 永远是 unicode 字符串,因此在我们把 id 发送给 Flask-SQLAlchemy 之前,把 id 转成整型是必须的,否则会报错!
登录视图函数¶
接下来我们需要更新我们的登录视图函数(文件 app/views.py):
from flask import render_template, flash, redirect, session, url_for, request, g
from flask.ext.login import login_user, logout_user, current_user, login_required
from app import app, db, lm, oid
from .forms import LoginForm
from .models import User
@app.route('/login', methods=['GET', 'POST'])
@oid.loginhandler
def login():
if g.user is not None and g.user.is_authenticated():
return redirect(url_for('index'))
form = LoginForm()
if form.validate_on_submit():
session['remember_me'] = form.remember_me.data
return oid.try_login(form.openid.data, ask_for=['nickname', 'email'])
return render_template('login.html',
title='Sign In',
form=form,
providers=app.config['OPENID_PROVIDERS'])
注意我们这里导入了不少新的模块,一些模块我们将会在不久后使用到。
跟之前的版本的改动是非常小的。我们在视图函数上添加一个新的装饰器。oid.loginhandle 告诉 Flask-OpenID 这是我们的登录视图函数。
在函数开始的时候,我们检查 g.user 是否被设置成一个认证用户,如果是的话将会被重定向到首页。这里的想法是如果是一个已经登录的用户的话,就不需要二次登录了。
Flask 中的 g 全局变量是一个在请求生命周期中用来存储和共享数据。我敢肯定你猜到了,我们将登录的用户存储在这里(g)。
我们在 redirect 调用中使用的 url_for 函数是定义在 Flask 中,以一种干净的方式为一个给定的视图函数获取 URL。如果你想要重定向到首页你可能会经常使用 redirect(‘/index’),但是有很多 好理由 让 Flask 为你构建 URLs。
当我们从登录表单获取的数据后的处理代码也是新的。这里我们做了两件事。首先,我们把 remember_me 布尔值存储到 flask 的会话中,这里别与 Flask-SQLAlchemy 中的 db.session 弄混淆。之前我们已经知道 flask.g 对象在请求整个生命周期中存储和共享数据。flask.session 提供了一个更加复杂的服务对于存储和共享数据。一旦数据存储在会话对象中,在来自同一客户端的现在和任何以后的请求都是可用的。数据保持在会话中直到会话被明确地删除。为了实现这个,Flask 为我们应用程序中每一个客户端设置不同的会话文件。
在接下来的代码行中,oid.try_login 被调用是为了触发用户使用 Flask-OpenID 认证。该函数有两个参数,用户在 web 表单提供的 openid 以及我们从 OpenID 提供商得到的数据项列表。因为我们已经在用户模型类中定义了 nickname 和 email,这也是我们将要从 OpenID 提供商索取的。
OpenID 认证异步发生。如果认证成功的话,Flask-OpenID 将会调用一个注册了 oid.after_login 装饰器的函数。如果失败的话,用户将会回到登陆页面。
Flask-OpenID 登录回调¶
这里就是我们的 after_login 函数的实现(文件 app/views.py):
@oid.after_login
def after_login(resp):
if resp.email is None or resp.email == "":
flash('Invalid login. Please try again.')
return redirect(url_for('login'))
user = User.query.filter_by(email=resp.email).first()
if user is None:
nickname = resp.nickname
if nickname is None or nickname == "":
nickname = resp.email.split('@')[0]
user = User(nickname=nickname, email=resp.email)
db.session.add(user)
db.session.commit()
remember_me = False
if 'remember_me' in session:
remember_me = session['remember_me']
session.pop('remember_me', None)
login_user(user, remember = remember_me)
return redirect(request.args.get('next') or url_for('index'))
resp 参数传入给 after_login 函数,它包含了从 OpenID 提供商返回来的信息。
第一个 if 只是为了验证。我们需要一个合法的邮箱地址,因此提供邮箱地址是不能登录的。
接下来,我们从数据库中搜索邮箱地址。如果邮箱地址不在数据库中,我们认为是一个新用户,因为我们会添加一个新用户到数据库。注意例子中我们处理空的或者没有提供的 nickname 方式,因为一些 OpenID 提供商可能没有它的信息。
接着,我们从 flask 会话中加载 remember_me 值,这是一个布尔值,我们在登录视图函数中存储的。
然后,为了注册这个有效的登录,我们调用 Flask-Login 的 login_user 函数。
最后,如果在 next 页没有提供的情况下,我们会重定向到首页,否则会重定向到 next 页。
如果要让这些都起作用的话,Flask-Login 需要知道哪个视图允许用户登录。我们在应用程序模块初始化中配置(文件 app/__init__.py):
lm = LoginManager()
lm.init_app(app)
lm.login_view = 'login'
全局变量 g.user¶
如果你观察仔细的话,你会记得在登录视图函数中我们检查 g.user 为了决定用户是否已经登录。为了实现这个我们用 Flask 的 before_request 装饰器。任何使用了 before_request 装饰器的函数在接收请求之前都会运行。 因此这就是我们设置我们 g.user 的地方(文件 app/views.py):
@app.before_request
def before_request():
g.user = current_user
这就是所有需要做的。全局变量 current_user 是被 Flask-Login 设置的,因此我们只需要把它赋给 g.user ,让访问起来更方便。有了这个,所有请求将会访问到登录用户,即使在模版里。
首页视图¶
在前面的章节中,我们的 index 视图函数使用了伪造的对象,因为那时候我们并没有用户或者 blog。好了,现在我们有用户了,让我们使用它:
@app.route('/')
@app.route('/index')
@login_required
def index():
user = g.user
posts = [
{
'author': { 'nickname': 'John' },
'body': 'Beautiful day in Portland!'
},
{
'author': { 'nickname': 'Susan' },
'body': 'The Avengers movie was so cool!'
}
]
return render_template('index.html',
title = 'Home',
user = user,
posts = posts)
上面仅仅只有两处变化。首先,我们添加了 login_required 装饰器。这确保了这页只被已经登录的用户看到。
另外一个变化就是我们把 g.user 传入给模版,代替之前使用的伪造对象。
这是运行应用程序最好的时候了!
登出¶
我们已经实现了登录,现在是时候增加登出的功能。
登出的视图函数是相当地简单(文件 app/views.py):
@app.route('/logout')
def logout():
logout_user()
return redirect(url_for('index'))
但是我们还没有在模版中添加登出的链接。我们将要把这个链接放在基础层中的导航栏里(文件 app/templates/base.html):
<html>
<head>
{% if title %}
<title>{{title}} - microblog</title>
{% else %}
<title>microblog</title>
{% endif %}
</head>
<body>
<div>Microblog:
<a href="{{ url_for('index') }}">Home</a>
{% if g.user.is_authenticated() %}
| <a href="{{ url_for('logout') }}">Logout</a>
{% endif %}
</div>
<hr>
{% with messages = get_flashed_messages() %}
{% if messages %}
<ul>
{% for message in messages %}
<li>{{ message }} </li>
{% endfor %}
</ul>
{% endif %}
{% endwith %}
{% block content %}{% endblock %}
</body>
</html>
实现起来是不是很简单?我们只需要检查有效的用户是否被设置到 g.user 以及是否我们已经添加了登出链接。我们也正好利用这个机会在模版中使用 url_for。
用户信息页和头像¶
回顾¶
在上一章中,我们已经完成了登录系统,因此我们可以使用 OpenIDs 登录以及登出。
今天,我们将要完成个人信息页。首先,我们将创建用户信息页,显示用户信息以及最近的 blog。作为其中一部分,我们将会学习到显示用户头像。接着,我们将要用户 web 表单用来编辑用户信息。
用户信息页¶
创建一个用户信息不需要引入新的概念。我们只要创建一个新的视图函数以及与它配套的 HTML 模版。
这里就是视图函数(文件 app/views.py):
@app.route('/user/<nickname>')
@login_required
def user(nickname):
user = User.query.filter_by(nickname = nickname).first()
if user == None:
flash('User ' + nickname + ' not found.')
return redirect(url_for('index'))
posts = [
{ 'author': user, 'body': 'Test post #1' },
{ 'author': user, 'body': 'Test post #2' }
]
return render_template('user.html',
user = user,
posts = posts)
我们用于这个视图函数的装饰器与之前的有些不同。在这个例子中,我们有一个 参数 在里面,用 <nickname> 来表示。这转化为一个同名的参数添加到视图函数。当客户端以 URL /user/miguel 请求的时候,视图函数收到一个 nickname = ‘miguel’ 参数而被调用。
视图函数的实现没有让人惊喜的。首先,我们使用接收到参数 nickname 试着从数据库载入用户。如果没有找到用户的话,我们将会抛出错误信息,重定向到主页。
一旦我们找到用户,我们把它传入到 render_template 调用, 并且传入一些伪造的 blog。注意在用户信息页上只会显示该用户的 blog,因此,我们伪造的 blog 的 author 域必须正确。
我们最初的视图模版是十分简单的(文件 app/templates/user.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<h1>User: {{user.nickname}}!</h1>
<hr>
{% for post in posts %}
<p>
{{post.author.nickname}} says: <b>{{post.body}}</b>
</p>
{% endfor %}
{% endblock %}
用户信息页现在已经完成了,但是缺少对它的链接。为了让用户很容易地检查他的或者她的信息,我们直接把用户信息页的链接放在导航栏中(文件 app/templates/base.html):
<div>Microblog:
<a href="{{ url_for('index') }}">Home</a>
{% if g.user.is_authenticated() %}
| <a href="{{ url_for('user', nickname = g.user.nickname) }}">Your Profile</a>
| <a href="{{ url_for('logout') }}">Logout</a>
{% endif %}
</div>
试试应用程序吧。点击导航栏中的个人资料链接,会把你带到用户信息页。因为我们还没有到任何用户的信息页的链接,因此你必须手动键入你想要看到的用户信息的 URL。比如,你可以键入 http://localhost:5000/user/miguel,查看 miguel 用户信息。
头像¶
我敢肯定你会同意我们的个人信息页是很无聊的。为了让他们有点更有趣,让我们添加用户头像。
不需要在我们自己的服务器处理大量的上传图片,我们依赖 Gravatar 服务为我们提供用户头像。
因为返回一个头像是与用户相关的任务,我们把它放在 User 类(文件 app/models.py):
from hashlib import md5
# ...
class User(db.Model):
# ...
def avatar(self, size):
return 'http://www.gravatar.com/avatar/' + md5(self.email).hexdigest() + '?d=mm&s=' + str(size)
User 的方法 avatar 返回用户图片的 URL,以像素为单位缩放成要求的尺寸。
有了 Gravatar 服务的协助,很容易处理头像。你只需要创建一个用户邮箱的 MD5 哈希,然后将其加入 URL中,像上面你看见的。在邮箱 MD5 后,你还需要提供一个定制头像尺寸的数字。d=mm 决定什么样的图片占位符当用户没有 Gravatar 账户。mm 选项将会返回一个“神秘人”图片,一个人灰色的轮廓。s=N 选项要求头像按照以像素为单位的给定尺寸缩放。
Gravatar 官方文档 对 avatar URL 有着更加详细的解释。
现在我们的 User 类知道怎样返回一个头像图片,我们把它融入到用户信息页的布局中(文件 app/templates/user.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<table>
<tr valign="top">
<td><img src="{{user.avatar(128)}}"></td>
<td><h1>User: {{user.nickname}}</h1></td>
</tr>
</table>
<hr>
{% for post in posts %}
<p>
{{post.author.nickname}} says: <b>{{post.body}}</b>
</p>
{% endfor %}
{% endblock %}
User 类负责返回头像是一个很巧妙的事情,如果有一天决定不想要 Gravatar 头像,我们只要重构 avatar 返回不同的 URLs(即使指向我们自己的服务器,如果我们想要自己的头像服务器),所有我们的模版将会自动地开始显示新的头像。
我们已经在用户信息页上添加了头像,如果我们想要在每一个 blog 前面显示头像了?这也是一个简单的工作,为了在每一个 blog 前显示头像,我们只需要在模块做一些小改变(文件 app/templates/user.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<table>
<tr valign="top">
<td><img src="{{user.avatar(128)}}"></td>
<td><h1>User: {{user.nickname}}</h1></td>
</tr>
</table>
<hr>
{% for post in posts %}
<table>
<tr valign="top">
<td><img src="{{post.author.avatar(50)}}"></td><td><i>{{post.author.nickname}} says:</i><br>{{post.body}}</td>
</tr>
</table>
{% endfor %}
{% endblock %}
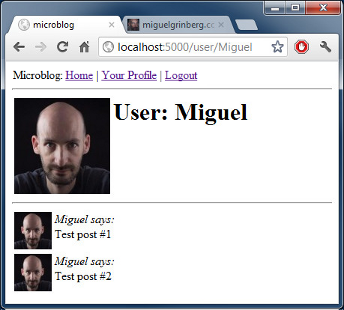
这就是我们的用户资料页的样子:
在子模板中重用¶
我们已经实现了用户信息页,它能够显示用户的 blog。我们的首页也应该显示任何一个用户这个时候的 blog 。这样我们有两个页需要显示用户的 blog。当然我们可以直接拷贝和复制处理渲染 blog 的模板,但这不是最理想的。因为当我们决定要修改 blog 的布局的时候,我们要更新所有使用它的模板。
相反,我们将要制作一个渲染 blog 的子模板,我们在使用它的模板中包含这个子模板。
我们创建一个 blog 的子模板,这是一个再普通不过的模板(文件 /app/templates/post.html):
<table>
<tr valign="top">
<td><img src="{{post.author.avatar(50)}}"></td><td><i>{{post.author.nickname}} says:</i><br>{{post.body}}</td>
</tr>
</table>
接着我们使用 Jinja2 的 include 命令在我们的用户模板中调用这个子模板(文件 app/templates/user.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<table>
<tr valign="top">
<td><img src="{{user.avatar(128)}}"></td>
<td><h1>User: {{user.nickname}}</h1></td>
</tr>
</table>
<hr>
{% for post in posts %}
{% include 'post.html' %}
{% endfor %}
{% endblock %}
一旦我们有一个功能上完全实现的首页,我们将会调用这个子模板,但是现在不准备这么做,将会把它留在后面的章节。
更多有趣的信息¶
尽然我们现在已经有一个不错的用户信息页,我们还有更多的信息需要在上面显示。像用户自我说明可以显示在用户信息页上,因此我们将会让用户写一些自我介绍,并将它们显示在用户资料页上。我们也将追踪每个用户访问页面的最后一次的时间,因此我们将会把它显示在用户信息页上。
为了增加这些,我们必须开始修改数据库。更具体地说,我们必须在我们的 User 类上增加两个字段(文件 app/models.py):
class User(db.Model):
id = db.Column(db.Integer, primary_key = True)
nickname = db.Column(db.String(64), unique = True)
email = db.Column(db.String(120), index = True, unique = True)
posts = db.relationship('Post', backref = 'author', lazy = 'dynamic')
about_me = db.Column(db.String(140))
last_seen = db.Column(db.DateTime)
前面的章节我们已经讲述过数据库的迁移。因此为了增加这两个新字段到数据库,需要运行升级脚本:
./db_migrate.py
脚本会返回如下信息:
New migration saved as db_repository/versions/003_migration.py
Current database version: 3
我们的两个新字段加入到我们的数据库。记得如果在 Windows 上的话,调用脚本的方式不同。
如果我们没有迁移的支持,我们必须手动地编辑数据库,最差的方式就是删除表再重新创建。
接着,让我们修改用户信息页模板来展示这些字段(文件 app/templates/user.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<table>
<tr valign="top">
<td><img src="{{user.avatar(128)}}"></td>
<td>
<h1>User: {{user.nickname}}</h1>
{% if user.about_me %}<p>{{user.about_me}}</p>{% endif %}
{% if user.last_seen %}<p><i>Last seen on: {{user.last_seen}}</i></p>{% endif %}
</td>
</tr>
</table>
<hr>
{% for post in posts %}
{% include 'post.html' %}
{% endfor %}
{% endblock %}
注意:我们利用 Jinja2 的条件语句来显示这些字段,因为只有当它们被设置的时候才会显示出来。
last_seen 字段能够被聪明地支持。记得在之前的章节中,我们创建了一个 before_request 函数,用来注册登录的用户到全局变量 flask.g 中。这个函数可以用来在数据库中更新用户最后一次的访问时间(文件 app/views.py):
from datetime import datetime
# ...
@app.before_request
def before_request():
g.user = current_user
if g.user.is_authenticated():
g.user.last_seen = datetime.utcnow()
db.session.add(g.user)
db.session.commit()
如果你登录到你的信息页,最后出现时间会显示出来。每次刷新页面,最后出现时间都会更新,因此每次浏览器在发送请求之前,before_request 函数都会在数据库中更新时间。
注意的是我们是以标准的 UTC 时区写入时间。我们在之前的章节中讨论过这个问题,因此我们将会以 UTC 格式写入所有时间内容以保证它们的一致性。这种时间形式在前台显示,看起来会很别扭。我们将会在后面的章节中修正这种显示问题。
要显示用户的关于我的信息,我们必须给他们输入的地方,在“编辑个人信息”页面,这是正确的地方。
编辑用户信息¶
新增一个用户信息表单是相当容易的。我们开始创建网页表单(文件 app/forms.py):
from flask.ext.wtf import Form
from wtforms import StringField, BooleanField, TextAreaField
from wtforms.validators import DataRequired, Length
class EditForm(Form):
nickname = StringField('nickname', validators=[DataRequired()])
about_me = TextAreaField('about_me', validators=[Length(min=0, max=140)])
接着视图模板(文件 app/templates/edit.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<h1>Edit Your Profile</h1>
<form action="" method="post" name="edit">
{{form.hidden_tag()}}
<table>
<tr>
<td>Your nickname:</td>
<td>{{form.nickname(size = 24)}}</td>
</tr>
<tr>
<td>About yourself:</td>
<td>{{form.about_me(cols = 32, rows = 4)}}</td>
</tr>
<tr>
<td></td>
<td><input type="submit" value="Save Changes"></td>
</tr>
</table>
</form>
{% endblock %}
最后我们编写视图函数(文件 app/views.py):
from forms import LoginForm, EditForm
@app.route('/edit', methods=['GET', 'POST'])
@login_required
def edit():
form = EditForm()
if form.validate_on_submit():
g.user.nickname = form.nickname.data
g.user.about_me = form.about_me.data
db.session.add(g.user)
db.session.commit()
flash('Your changes have been saved.')
return redirect(url_for('edit'))
else:
form.nickname.data = g.user.nickname
form.about_me.data = g.user.about_me
return render_template('edit.html', form=form)
为了能够让这页很容易访问到,我们在用户信息页上添加了一个链接(文件 app/templates/user.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<table>
<tr valign="top">
<td><img src="{{user.avatar(128)}}"></td>
<td>
<h1>User: {{user.nickname}}</h1>
{% if user.about_me %}<p>{{user.about_me}}</p>{% endif %}
{% if user.last_seen %}<p><i>Last seen on: {{user.last_seen}}</i></p>{% endif %}
{% if user.id == g.user.id %}<p><a href="{{url_for('edit')}}">Edit</a></p>{% endif %}
</td>
</tr>
</table>
<hr>
{% for post in posts %}
{% include 'post.html' %}
{% endfor %}
{% endblock %}
编辑用户信息的链接是十分智能的,只有当用户浏览自己的用户信息页的时候才会出现,浏览其他用户的时候是不会出现的。
下面用户信息页的新的截图:
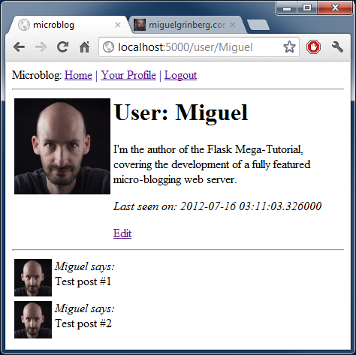
结束语¶
最后留给大家一个问题,应用程序存在一个 bug。这个问题在前面的章节就已经存在,这一章的代码存在同样的问题。在下一章中我会解释这个 bug,并且修正它。
如果你想要节省时间的话,你可以下载 microblog-0.6.zip。
请记住数据库并不包含在上述的压缩包中,请使用 db_upgrade.py 升级数据库,用 db_create.py 创建新的数据库。
我希望能在下一章继续见到各位!
单元测试¶
回顾¶
在上一章中我们集中在一步一步为我们的应用程序的添加功能。到目前为止,我们有一个数据库功能的应用程序,它能够注册用户,允许用户登录以及登出,查看以及编辑他们的用户信息。
在本章中,我们不打算添加新的特性。相反,我们将要寻找方式来保证我们编写的代码的健壮性,我们也创建了一个测试框架用来帮助我们避免将来的失败和回归测试。
发现 bug¶
我记得在上一章结尾的时候,我特意提出了应用程序存在 bug。让我来描述下 bug 是什么,接着看看当不按预期工作的时候(bug 出现的时候),我们的应用程序会发生什么。
应用程序中的 bug 就是没有有效的让我们用户的昵称保持唯一性。应用程序自动选择用户的初始昵称。如果 OpenID 提供商提供一个用户的昵称的话我们会使用这个昵称。如果没有提供话,应用程序会选择邮箱的用户名部分作为昵称。如果两个用户有着同样的昵称的话,第二个用户是不能够被注册的。更加糟糕的是,在编辑用户信息的时候,我们允许用户修改昵称,但是没有去限制昵称名称冲突。
我们将会在分析 bug 发生时候应用程序的的行为后修正这些问题。
Flask 调试¶
让我们来看看当我们触发一个 bug 的时候会发生些什么。
先让我们创建一个新的数据库。在 Linux:
rm app.db
./db_create.py
或者在 Windows 上:
del app.db
flask/Scripts/python db_create.py
为了重现这个 bug,你需要两个 OpenID 账号,理想地是不同的提供商,从而使得它们的 cookies 不会太复杂。遵照这些步骤创建一个重复的昵称:
- 登录你的第一个账号
- 进入到编辑用户信息页并且把昵称改为’dup’
- 登出
- 登录第二个账号
- 进入到编辑用户信息页并且把昵称改为’dup’
糟糕!我们已经得到了来自 SQLAlchemy 的一个异常。错误的信息写着:
sqlalchemy.exc.IntegrityError
IntegrityError: (IntegrityError) column nickname is not unique u'UPDATE user SET nickname=?, about_me=? WHERE user.id = ?' (u'dup', u'', 2)
紧跟着错误后面的是错误的 堆栈跟踪,这是一个相当不错的东西,在这里你可以去任何一帧并且检查源代码或者甚至在浏览器正确地上计算表达式。
错误是相当地明显的,我们试着在数据库中插入重复的昵称。数据库模型对 nickname 字段有着 unique 限制,因此这不是一个合法的操作。
除了实际的错误,我们面前还有另外一个问题。如果一个用户不幸在我们的应用程序中遇到一个错误(这个或者其它的引起的异常)他或者她将会得到错误消息和堆栈跟踪,然而他们只是用户不是开发者。尽管这其实是一个很梦幻般的功能当我们开发的时候,但是这也是我们绝对不希望我们的用户能够看到的东西。
这段时间内我们的应用程序以调试模式运行着。调试模式是在应用程序运行的时候通过在 run 方法中传入参数 debug = True。
当我们在开发的应用程序的时候这个功能很方便,但是我们必须在生产环境上确保这个功能被禁用。让我们创建另外一个调试模式禁用的启动脚本(文件 runp.py):
#!flask/bin/python
from app import app
app.run(debug = False)
现在重启应用程序:
./runp.py
接着重新尝试修改第二个账号的昵称为 ‘dup’。
这个时候我们不会得到一个前面出现的错误。相反,我们会得到一个 HTTP 错误 500,这是服务器内部错误。尽管还是返回一个错误,但至少不暴露我们的应用程序的任何细节给陌生人。当调试关闭,500 错误页是由 Flask 产生的并且发生了未处理的异常。
虽然情况有些好转,我们现在有两个新的问题。第一个是外观上的:默认的 500 错误页很丑陋。第二个小问题相当重要。我们可能不会知道什么时候用户会在我们的程序中会遇到一个失败因为现在调试被禁用。幸好有两种简单的方式解决这两个问题。
定制 HTTP 错误处理器¶
Flask 为应用程序提供了一种安装自己的错误页的机制。作为例子,让我们自定义 HTTP 404 以及 500 错误页,这是最常见的两个。定义其它错误的方式是一样的。
为了声明一个定制的错误处理器,需要使用装饰器 errorhandler (文件 app/views.py):
@app.errorhandler(404)
def internal_error(error):
return render_template('404.html'), 404
@app.errorhandler(500)
def internal_error(error):
db.session.rollback()
return render_template('500.html'), 500
上面的不需要多做解释,代码很清楚,唯一值得感兴趣就是在错误 500 处理器中的 rollback 声明。这是很有必要的因为这个函数是被作为异常的结果被调用。如果异常是被一个数据库错误触发,数据库的会话会处于一个不正常的状态,因此我们必须把会话回滚到正常工作状态在渲染 500 错误页模板之前。
这是 404 错误的模板:
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<h1>File Not Found</h1>
<p><a href="{{url_for('index')}}">Back</a></p>
{% endblock %}
这是 500 错误的一个模板:
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<h1>An unexpected error has occurred</h1>
<p>The administrator has been notified. Sorry for the inconvenience!</p>
<p><a href="{{url_for('index')}}">Back</a></p>
{% endblock %}
注意的是在上面两个模板中我们继续使用我们 base.html 布局,这是为了让错误页面和应用程序的外观是统一的。
通过电子邮件发送错误¶
为了解决我们第二个问题,我们将会配置两种应用程序错误报告机制。第一个就是当错误发生的时候发送电子邮件。
在开始之前我们先在应用程序中配置邮件服务器以及管理员邮箱地址(文件 config.py):
# mail server settings
MAIL_SERVER = 'localhost'
MAIL_PORT = 25
MAIL_USERNAME = None
MAIL_PASSWORD = None
# administrator list
ADMINS = ['[email protected]']
Flask 使用 Python logging 模块,因此当发生异常的时候发送邮件是十分简单(文件 app/__init__.py):
from config import basedir, ADMINS, MAIL_SERVER, MAIL_PORT, MAIL_USERNAME, MAIL_PASSWORD
if not app.debug:
import logging
from logging.handlers import SMTPHandler
credentials = None
if MAIL_USERNAME or MAIL_PASSWORD:
credentials = (MAIL_USERNAME, MAIL_PASSWORD)
mail_handler = SMTPHandler((MAIL_SERVER, MAIL_PORT), 'no-reply@' + MAIL_SERVER, ADMINS, 'microblog failure', credentials)
mail_handler.setLevel(logging.ERROR)
app.logger.addHandler(mail_handler)
在一个没有邮件服务器的开发机器上测试上述代码是相当容易的,多亏了 Python 的 SMTP 调试服务器。仅需要打开一个新的命令行窗口(Windows 用户打开命令提示符)接着运行如下内容打开一个伪造的邮箱服务器:
python -m smtpd -n -c DebuggingServer localhost:25
当邮箱服务器运行后,应用程序发送的邮件将会被接收到并且显示在命令行窗口上。
记录到文件¶
通过邮件接收错误是不错的,但是有时候这并不够。有些失败并不是结束于异常而且也不是主要问题,然而我们可能想要在日志中追踪它们以便做一些调试。
出于这个原因,我们还要为应用程序保持一个日志文件。
启用日志记录类似于电子邮件发送错误(文件 app/__init__.py):
if not app.debug:
import logging
from logging.handlers import RotatingFileHandler
file_handler = RotatingFileHandler('tmp/microblog.log', 'a', 1 * 1024 * 1024, 10)
file_handler.setFormatter(logging.Formatter('%(asctime)s %(levelname)s: %(message)s [in %(pathname)s:%(lineno)d]'))
app.logger.setLevel(logging.INFO)
file_handler.setLevel(logging.INFO)
app.logger.addHandler(file_handler)
app.logger.info('microblog startup')
日志文件将会在 tmp 目录,名称为 microblog.log。我们使用了 RotatingFileHandler 以至于生成的日志的大小是有限制的。在这个例子中,我们的日志文件的大小限制在 1 兆,我们将保留最后 10 个日志文件作为备份。
logging.Formatter 类能够定制化日志信息的格式。由于这些信息记录到一个文件中,我们希望它们提供尽可能多的信息,所以我们写一个时间戳,日志记录级别和消息起源于以及日志消息和堆栈跟踪的文件和行号。
为了使得日志更有作用,我们降低了应用程序日志以及文件日志处理器的级别,这样给我们机会写入有用的信息到日志并不是必须错误发生的时候。从这以后,每次你以非调试模式启动有用程序,日志将会记录事件。
虽然我们不会在这个时候有很多记录器的需求,调试的一个处于联机状态并在使用中的网页服务器是非常困难的。消息记录到一个文件,是一个非常有用的工具,在诊断和定位问题,所以我们现在都准备好,我们需要使用此功能。
修复 bug¶
让我们解决 nickname 重复的问题。
像之前讨论的,目前存在两个地方没有处理重复。第一个就是在 after_login 函数。当一个用户成功地登录进系统这个函数就会被调用,这里我们需要创建一个新的 User 实例。这里就是受影响的代码块(文件 app/views.py):
if user is None:
nickname = resp.nickname
if nickname is None or nickname == "":
nickname = resp.email.split('@')[0]
nickname = User.make_unique_nickname(nickname)
user = User(nickname = nickname, email = resp.email)
db.session.add(user)
db.session.commit()
解决问题的方式就是让 User 类为我们选择一个唯一的名字。这就是新的 make_unique_nickname 方法所做的(文件 app/models.py):
class User(db.Model):
# ...
@staticmethod
def make_unique_nickname(nickname):
if User.query.filter_by(nickname = nickname).first() == None:
return nickname
version = 2
while True:
new_nickname = nickname + str(version)
if User.query.filter_by(nickname = new_nickname).first() == None:
break
version += 1
return new_nickname
# ...
这种方法简单地增加一个计数器为请求的昵称,直到找到一个唯一的名称。例如,如果用户名 “miguel”已经存在,这个方法将会建议使用 “miguel2”,如果这个还是存在,将会建议使用 “miguel3”,依次下去直至找到唯一的用户名。需要注意的是我们把这个方法作为一个静态方法,因为这种操作并不适用于任何特定的类的实例。
第二个存在重复昵称问题的地方就是编辑用户信息的视图函数。这个稍微有些难处理,因为这是用户自己选择的昵称。正确的做法就是不接受一个重复的昵称,让用户重新输入一个。我们将通过添加一个昵称表单字段定制化的验证来解决这个问题。如果用户输入一个不合法的昵称,字段的验证将会失败,用户将会返回到编辑用户信息页。为了添加验证,我们只需覆盖表单的 validate 方法(文件 app/forms.py):
from app.models import User
class EditForm(Form):
nickname = StringField('nickname', validators=[DataRequired()])
about_me = TextAreaField('about_me', validators=[Length(min=0, max=140)])
def __init__(self, original_nickname, *args, **kwargs):
Form.__init__(self, *args, **kwargs)
self.original_nickname = original_nickname
def validate(self):
if not Form.validate(self):
return False
if self.nickname.data == self.original_nickname:
return True
user = User.query.filter_by(nickname=self.nickname.data).first()
if user != None:
self.nickname.errors.append('This nickname is already in use. Please choose another one.')
return False
return True
表单的初始化新增了一个参数 original_nickname。validate 方法使用它来决定昵称什么时候更改过。如果没有发生更改就接受它。如果已经发生更改的话,确保昵称在数据库是唯一的。
在视图函数中传入这个参数:
@app.route('/edit', methods = ['GET', 'POST'])
@login_required
def edit():
form = EditForm(g.user.nickname)
# ...
为了完成这个修改,我们必须在表单模板中使得字段错误信息会显示(文件 app/templates/edit.html):
<td>Your nickname:</td>
<td>
{{form.nickname(size = 24)}}
{% for error in form.errors.nickname %}
<br><span style="color: red;">[{{error}}]</span>
{% endfor %}
</td>
现在问题是修复了,重复将会被禁止。。。除非是都没有。我们仍然存在潜在的问题,当两个或者更多的线程或者处理同时访问数据库的时候,但是这将会是以后的话题。
单元测试框架¶
在结束本章的话题之前,让我们来讨论一点自动化测试。
随着应用程序的规模变得越大就越难保证代码的修改不会影响到现有的功能。
传统的方式–回归测试是一个很好的主意。你编写测试检验应用程序所有不同的功能。每一个测试集中在一个关注点上验证结果是不是期望的。定期执行测试确保应用程序按预期的工作。当测试覆盖很大的时候,通过运行测试你就有自信确保修改点和新增点不会影响应用程序。
我们使用 Python 的 unittest 模块将会构建一个简单的测试框架(文件 tests.py):
#!flask/bin/python
import os
import unittest
from config import basedir
from app import app, db
from app.models import User
class TestCase(unittest.TestCase):
def setUp(self):
app.config['TESTING'] = True
app.config['WTF_CSRF_ENABLED'] = False
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'test.db')
self.app = app.test_client()
db.create_all()
def tearDown(self):
db.session.remove()
db.drop_all()
def test_avatar(self):
u = User(nickname='john', email='[email protected]')
avatar = u.avatar(128)
expected = 'http://www.gravatar.com/avatar/d4c74594d841139328695756648b6bd6'
assert avatar[0:len(expected)] == expected
def test_make_unique_nickname(self):
u = User(nickname='john', email='[email protected]')
db.session.add(u)
db.session.commit()
nickname = User.make_unique_nickname('john')
assert nickname != 'john'
u = User(nickname=nickname, email='[email protected]')
db.session.add(u)
db.session.commit()
nickname2 = User.make_unique_nickname('john')
assert nickname2 != 'john'
assert nickname2 != nickname
if __name__ == '__main__':
unittest.main()
讨论 unittest 模块是在本文的范围之外的。TestCase 类中含有我们的测试。setUp 和 tearDown 方法是特别的,它们分别在测试之前以及测试之后运行。
在上面代码中 setUp 和 tearDown 方法十分普通。在 setUp 中做了一些配置,在 tearDown 中重置数据库内容。
测试实现成了方法。一个测试支持运行应用程序的多个函数,并且有已知的结果以及应该断言结果是否不同于预期的。
目前为止在测试框架中有两个测试。第一个就是验证 Gravatar 的头像 URL生成是否正确。注意测试中期待的结果是硬编码,验证 User 类的返回的头像 URL。
第二个就是我们前面编写的 make_unique_nickname 方法,同样是在 User 类中。
为了运行测试套件你只要运行 tests.py 脚本:
python tests.py
如果没有什么错误的话,你将会在控制台中得到测试报告。
关注者,联系人和好友¶
回顾¶
我们小型的 microblog 应用程序已经慢慢变大,到现在为止我们已经接触了需要完成应用程序的大部分的话题。
今天我们将更加深入地学习数据库。我们应用程序的每一个用户都能够选择他或者她的关注者,因此我们的数据库必须能够记录谁关注了谁。所有的社交应用都会以某种形式实现这个功能。一些应用程序称它为联系人,其他连接,好友,伙伴或者关注者。其他的站点使用同样的主意去实现允许和忽略的用户列表。我们称它为关注者,尽管名字不同实现方式却是一样的。
‘关注者’ 特色的设计¶
在编码之前,我们需要考虑下我们要从这个功能上得到些什么,换句话说,我们要实现些什么。
让我们先从最明显一个开始。我们想要用户容易地维护关注者的列表。
从另外一方面来看,对于每一个用户,我们想要知道他的或者她的关注者列表。
我们也想要有一种方式去查询用户是否被关注或者关注过其他用户。
用户点击任何用户的信息页上一个 “关注” 的链接就开始关注这个用户。否则,他们点击 “取消关注” 链接将会停止关注这个用户。
最后一个需求就是对于一个给定的用户,我们能够容易地查询数据库获取用户的被关注者的所有 blog。
所以,如果你认为这将是一个快速和容易的章节,请再想想!
数据库关系¶
我们说过我们想要有所有用户都拥有 “关注者” 和 “被关注者” 的列表。不幸地是,一个关系型数据库是没有 list 类型,我们有的是含有记录的表以及记录与记录之间的关系。
我们已经在数据库中有一个表来表示用户,所以剩下的就是找出适当的关系类型,它能模拟关注者/被关注者的链接。这是重新回顾三种数据关系类型的好时候:
一对多¶
在前面的章节中,我们已经见过一对多的关系。下面是这种关系的图表:
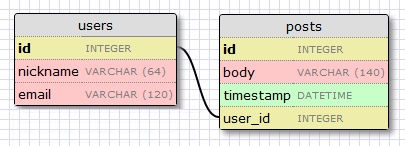
users 和 posts 是具有这种关系的两个表。我们说一个用户会有撰写多篇 blog,一篇 blog 会有一个撰写人。这种关系在数据库中的表示就是在 “多” 的这一边中使用了外键。在上面的例子中外键就是 posts 表中的 user_id。 这个字段把每一篇 blog 链接到用户表的作者的数据记录上。
user_id 字段提供了到给定 blog 作者的直接入口,然而相反的情况了?因为关系是很有作用的,我们应该能够得到一个给定的用户所撰写的 blog 列表。原来在 posts 表中 user_id 字段是足够能够回答这个问题,因为数据库有高效的查询索引允许我们查询类似 “获取用户 user_id 为 X 的所有的 blog” 的操作。
多对多¶
多对多的关系是有些复杂。例如,考虑一个数据库有 students 以及 teachers。我们可以说一个学生会有很多个老师,以及一个老师下也有多个学生。这就像两端(学生和老师)都是一对多的关系。
对于这种类型的关系,我们应该能够查询数据库获取在一个 teachers 类中教某一个学生的老师列表,以及一个老师下所有教的学生的列表。表示上述关系是相当棘手的,它不能简单地在已存在的表中添加外键。
这种多对多的关系的表示需要一个额外的称为关联表的辅助表。下面是数据库如何表示学生和教师的关系的例子:
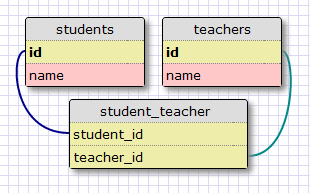
虽然它可能不会看起来很简单,两个外键的关联表能够有效地回答很多种类的查询,如:
- 哪些老师教学生 S?
- 哪些学生是老师 T 教的?
- 老师 T 有多少个学生?
- 学生 S 有多少个老师?
- 老师 T 正在教学生 S 吗?
- 学生 S 在老师 T 的类里吗?
一对一¶
一对一的关系是一对多关系的一种特殊情况。表示方式是类似的,但是限制是添加到数据库中为了禁止 “多” 的这一边有一个以上的链接。
虽然某些情况下,这种类型的关系是有用的,它对其他两种类型来说是不常用,因为任何时候一个表的一个记录映射到另外一个表中的一个记录,可以说把两个表合并成一个更有意义。
表示关注者和被关注者¶
从上面讲述到关系来说,我们很容易地决定最合适的模型是多对多的关系,因为一个用户可以关注多个其他的用户,同样一个用户可以被其他多个用户关注。但是这有一个问题。我们想要表示用户关注其他用户,因为我们只有用户。我们应该使用什么作为多对多关系的第二个表(实体)?
好的,这种关系的第二个表(实体)也是用户。如果一个表是指向自己的关系叫做 自我指向 关系,这就是我们现在需要的。
下面是多对多关系的图:
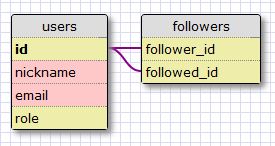
followers 表示我们的关联表。外键都是来自于用户表中,因为我们是用户连接到用户。在这个表中的每一个记录都是表示关注的用户以及被关注的用户的连接。像学生和老师的例子,像这样的一个设置允许回答所有我们将需要的关注者以及被关注者的问题。
数据模型¶
我们数据库的改变不是很大。我们首先开始添加 followers 表(文件 app/models.py):
followers = db.Table('followers',
db.Column('follower_id', db.Integer, db.ForeignKey('user.id')),
db.Column('followed_id', db.Integer, db.ForeignKey('user.id'))
)
这是对上面图表上的关系表的直接翻译。注意我们并没有像对 users 和 posts 一样把它声明为一个模式。因为这是一个辅助表,我们使用 flask-sqlalchemy 中的低级的 APIs 来创建没有使用关联模式。
接着我们在 users 表中定义一个多对多的关系:
class User(db.Model):
id = db.Column(db.Integer, primary_key = True)
nickname = db.Column(db.String(64), unique = True)
email = db.Column(db.String(120), index = True, unique = True)
posts = db.relationship('Post', backref = 'author', lazy = 'dynamic')
about_me = db.Column(db.String(140))
last_seen = db.Column(db.DateTime)
followed = db.relationship('User',
secondary = followers,
primaryjoin = (followers.c.follower_id == id),
secondaryjoin = (followers.c.followed_id == id),
backref = db.backref('followers', lazy = 'dynamic'),
lazy = 'dynamic')
关系的设置不是很简单,需要一些解释。像我们在前面章节设置一对多关系一样,我们使用了 db.relationship 函数来定义关系。我们将连接 User 实例到其它 User 实例,换一种通俗的话来说,在这种关系下连接的一对用户,左边的用户是关注着右边的用户。因为我们定义左边的用户为 followed,当我们从左边用户查询这种关系的时候,我们将会得到被关注用户的列表。让我们一个一个来解释下 db.relationship() 中的所有参数:
- ‘User’ 是这种关系中的右边的表(实体)(左边的表/实体是父类)。因为定义一个自我指向的关系,我们在两边使用同样的类。
- secondary 指明了用于这种关系的辅助表。
- primaryjoin 表示辅助表中连接左边实体(发起关注的用户)的条件。注意因为 followers 表不是一个模式,获得字段名的语法有些怪异。
- secondaryjoin 表示辅助表中连接右边实体(被关注的用户)的条件。
- backref 定义这种关系将如何从右边实体进行访问。当我们做出一个名为 followed 的查询的时候,将会返回所有跟左边实体联系的右边的用户。当我们做出一个名为 followers 的查询的时候,将会返回一个所有跟右边联系的左边的用户。lazy 指明了查询的模式。dynamic 模式表示直到有特定的请求才会运行查询,这是对性能有很好的考虑。
- lazy 是与 backref 中的同样名称的参数作用是类似的,但是这个是应用于常规查询。
如果上面的解释很难理解的话,没有关系。我们会在后面使用这些查询,一切就会明了。
因为我们对数据库做出了修改,现在我们必须生成一个新的迁移脚本:
./db_migrate.py
添加和移除 ‘关注者’¶
为了使得代码具有可重用性,我们将会在 User 模型中实现 follow 和 unfollow 函数,而不是在视图函数中。这种方式不仅可以让这个功能应用于真实的应用也能在单元测试中测试。原则上,从视图函数中移除应用程序的逻辑到数据模型中是一种好的方式。你们必须要保证视图函数尽可能简单,因为它能难被自动化测试。
下面是添加了添加和移除 ‘关注者’ 功能的 User 模型(文件 app/models.py):
class User(db.Model):
#...
def follow(self, user):
if not self.is_following(user):
self.followed.append(user)
return self
def unfollow(self, user):
if self.is_following(user):
self.followed.remove(user)
return self
def is_following(self, user):
return self.followed.filter(followers.c.followed_id == user.id).count() > 0
上面这些方法是很简单了,多亏了 sqlalchemy 在底层做了很多的工作。我们只是从 followed 关系中添加或者移除了表项,sqlalchemy 为我们管理辅助表。
follow 和 unfollow 方法是定义成当它们成功的话返回一个对象或者失败的时候返回 None。当返回一个对象的时候,这个对象必须被添加到数据库并且提交。
is_following 方法在一行代码中做了很多。我们做了一个 followed 关系查询,这个查询返回所有当前用户作为关注者的 (follower, followed) 对。
测试¶
让我们编写单元测试框架来检验目前我们已经写好的代码(文件 tests.py):
class TestCase(unittest.TestCase):
#...
def test_follow(self):
u1 = User(nickname = 'john', email = '[email protected]')
u2 = User(nickname = 'susan', email = '[email protected]')
db.session.add(u1)
db.session.add(u2)
db.session.commit()
assert u1.unfollow(u2) == None
u = u1.follow(u2)
db.session.add(u)
db.session.commit()
assert u1.follow(u2) == None
assert u1.is_following(u2)
assert u1.followed.count() == 1
assert u1.followed.first().nickname == 'susan'
assert u2.followers.count() == 1
assert u2.followers.first().nickname == 'john'
u = u1.unfollow(u2)
assert u != None
db.session.add(u)
db.session.commit()
assert u1.is_following(u2) == False
assert u1.followed.count() == 0
assert u2.followers.count() == 0
通过执行下面的命令来运行这个测试:
./tests.py
数据库查询¶
我们的数据库模型已经能够支持大部分我们列出来的需求。我们缺少的实际上是最难的。我们的首页将会显示登录用户所有关注者撰写的 blog,因为我们需要一个返回这些 blog 的查询。
最明了的解决方式就是查询给定的关注者用户的列表,这也是我们目前可以做到的。接着对每一个返回的用户去查询他的或者她的 blog。一旦我们完成所有的查询工作,我们把它们整合到一个列表中然后排序。听起来不错?实际上不是。
这种方法其实问题很大。当一个用户拥有上千个关注者的话会发生些什么?我们需要执行上千次甚至更多的数据库查询,并且在内存中我们需要维持一个数据量很大的 blog 的列表,接着还要排序。不知道这些做完,要花上多久的时间?
这种收集以及排序的工作需要在其它的地方完成,我们只要使用结果就行。这类的工作其实就是关系型数据库擅长。数据库有索引,因此允许以一种高效地方式去查询以及排序。
所以我们真正想要的是要拿出一个单一的数据库查询,表示我们想要得到什么样的信息,然后我们让数据库弄清楚什么是最有效的方式来为我们获取数据。
下面这种查询可以实现上述的要求,这个单行的代码又被我们添加到 User 模型(文件 app/models.py):
class User(db.Model):
#...
def followed_posts(self):
return Post.query.join(followers, (followers.c.followed_id == Post.user_id)).filter(followers.c.follower_id == self.id).order_by(Post.timestamp.desc())
让我们来分解这个查询。它一共有三部分:连接,过滤以及排序。
连接¶
为了理解一个连接操作做了什么,让我们看看例子。假设我们有一个如下内容的 User 表:

只为了简化例子,表里面还有一些额外的字段没有显示。
比如说,我们的 followers 辅助表中表示用户 “john” 关注着 用户 “susan” 以及 “david”,用户 “susan” 关注着 “mary” 以及 用户 “mary” 关注着 “david”。表示上述的数据是这样的:

最后,我们的 Post 表中,每一个用户有一篇 blog:

这里再次申明为了使得例子显得简单,我们忽略了一些字段。
下面是我们的查询的连接部分的,独立于其余的查询:
Post.query.join(followers,
(followers.c.followed_id == Post.user_id))
在 Post 表中调用了 join 操作。这里有两个参数,第一个是其它的表,我们的 followers 表。第二参数就是连接的条件。
连接操作所做的就是创建一个数据来自于 Post 和 followers 表的临时新的表,根据给定条件进行整合。
在这个例子中,我们要 followers 表中的字段 followed_id 与 Post 表中的字段 user_id 相匹配。
为了演示整合的过程,我们从 Post 表中取出所有记录,从 followers 表中取出符合条件的记录插入在后边。如果没有匹配的话,Post 表中的记录就会被移除。
我们例子中这个临时表的连接的结果如下:

注意 Post 表中的 user_id=1 记录被移除了,因为在 followers 表中没有 followed_id=1 的记录。
过滤¶
连接操作给我们被某人关注的用户的 blog 的列表,但是没有指出谁是关注者。我们仅仅对这个列表的子集感兴趣,我们只需要被某一特定用户关注的用户的 blog 列表。
因此我们过滤这个表格,查询的过滤操作是:
filter(followers.c.follower_id == self.id)
注意查询是在我们目标用户的内容中执行,因为这是 User 类的一个方法,self.id 就是我们感兴趣的用户的 id。因此在我们的例子中,如果我们感兴趣的用户的 id 是 id=1,那么我们会得到另一个临时表:

这就是我们要的 blog。请注意查询是关注在 Post 类,因此即使我们得到一个不符合我们任何一个数据库模型的临时表,结果还是包含在这个临时表中的 blog。
排序¶
最后一步就是根据我们的规则对结果进行排序。排序操作如下:
order_by(Post.timestamp.desc())
在这里,我们要说的结果应该按照 timestamp 字段按降序排列,这样的第一个结果将是最近的 blog。
这里还有一个小问题需要我们改善我们的查询操作。当用户阅读他们关注者的 blog 的时候,他们可能也想看到自己的 blog。因此最好把用户自己的 blog 也包含进查询结果中。
其实这不需要做任何改变。我们只需要把自己添加为自己的关注者。
为了结束我们长时间的查询操作的讨论,让我们为我们查询写些单元测试(文件 tests.py):
#...
from datetime import datetime, timedelta
from app.models import User, Post
#...
class TestCase(unittest.TestCase):
#...
def test_follow_posts(self):
# make four users
u1 = User(nickname = 'john', email = '[email protected]')
u2 = User(nickname = 'susan', email = '[email protected]')
u3 = User(nickname = 'mary', email = '[email protected]')
u4 = User(nickname = 'david', email = '[email protected]')
db.session.add(u1)
db.session.add(u2)
db.session.add(u3)
db.session.add(u4)
# make four posts
utcnow = datetime.utcnow()
p1 = Post(body = "post from john", author = u1, timestamp = utcnow + timedelta(seconds = 1))
p2 = Post(body = "post from susan", author = u2, timestamp = utcnow + timedelta(seconds = 2))
p3 = Post(body = "post from mary", author = u3, timestamp = utcnow + timedelta(seconds = 3))
p4 = Post(body = "post from david", author = u4, timestamp = utcnow + timedelta(seconds = 4))
db.session.add(p1)
db.session.add(p2)
db.session.add(p3)
db.session.add(p4)
db.session.commit()
# setup the followers
u1.follow(u1) # john follows himself
u1.follow(u2) # john follows susan
u1.follow(u4) # john follows david
u2.follow(u2) # susan follows herself
u2.follow(u3) # susan follows mary
u3.follow(u3) # mary follows herself
u3.follow(u4) # mary follows david
u4.follow(u4) # david follows himself
db.session.add(u1)
db.session.add(u2)
db.session.add(u3)
db.session.add(u4)
db.session.commit()
# check the followed posts of each user
f1 = u1.followed_posts().all()
f2 = u2.followed_posts().all()
f3 = u3.followed_posts().all()
f4 = u4.followed_posts().all()
assert len(f1) == 3
assert len(f2) == 2
assert len(f3) == 2
assert len(f4) == 1
assert f1 == [p4, p2, p1]
assert f2 == [p3, p2]
assert f3 == [p4, p3]
assert f4 == [p4]
可能的改进¶
我们现在已经实现 ‘follower’ 功能所需要的内容,但是还能改进我们的设计使得变得更加合理。
所有的社会网络,我们对这种连接其它用户的功能是又爱又恨,但他们有更多的选择来控制信息的共享。
例如,我们没有权利拒绝别人的关注。这将要花费很大的底层代码用于查询,因为我们不仅仅需要查询到我们所关注的用户的 blog,而且还要过滤掉拒绝关注的用户的 blog。怎么实现这种需求了?简单,新增一个多对多的自我指向关系用来记录谁拒绝谁的关注,接着一个新的连接+过滤的查询用来返回这些 blog。
社交网络中另一个流行的特色就是能够定制关注者的分组,仅仅共享某些分组的内容。这也是能够通过添加额外的关系以及复杂的查询来实现。
我们不打算把这些加入到我们的 microblog,但是如果大家都感兴趣的话,我将会就此话题新写一章节。
收尾¶
今天我们已经取得了巨大的进步。尽管我们已经解决了所有的问题,但是有关数据库的设置和查询,我们还没有在应用程序中启用的这些新功能。
幸运地是,这些不存在什么挑战。我们只需要修改下视图函数和模版,因此让我们完成最后的部分来结束这一章节吧。
成为自己的关注者¶
我们已经决定用户可以关注所有的用户,因此我们可以关注自己。
我们决定在 after_login 中处理 OpenID 的时候就设置自己成为自己的关注者(文件 app/views.py):
@oid.after_login
def after_login(resp):
if resp.email is None or resp.email == "":
flash('Invalid login. Please try again.')
redirect(url_for('login'))
user = User.query.filter_by(email = resp.email).first()
if user is None:
nickname = resp.nickname
if nickname is None or nickname == "":
nickname = resp.email.split('@')[0]
nickname = User.make_unique_nickname(nickname)
user = User(nickname = nickname, email = resp.email)
db.session.add(user)
db.session.commit()
# make the user follow him/herself
db.session.add(user.follow(user))
db.session.commit()
remember_me = False
if 'remember_me' in session:
remember_me = session['remember_me']
session.pop('remember_me', None)
login_user(user, remember = remember_me)
return redirect(request.args.get('next') or url_for('index'))
关注以及取消关注的链接¶
接着,我们将会定义关注以及取消关注用户的视图函数(文件 app/views.py):
@app.route('/follow/<nickname>')
@login_required
def follow(nickname):
user = User.query.filter_by(nickname=nickname).first()
if user is None:
flash('User %s not found.' % nickname)
return redirect(url_for('index'))
if user == g.user:
flash('You can\'t follow yourself!')
return redirect(url_for('user', nickname=nickname))
u = g.user.follow(user)
if u is None:
flash('Cannot follow ' + nickname + '.')
return redirect(url_for('user', nickname=nickname))
db.session.add(u)
db.session.commit()
flash('You are now following ' + nickname + '!')
return redirect(url_for('user', nickname=nickname))
@app.route('/unfollow/<nickname>')
@login_required
def unfollow(nickname):
user = User.query.filter_by(nickname=nickname).first()
if user is None:
flash('User %s not found.' % nickname)
return redirect(url_for('index'))
if user == g.user:
flash('You can\'t unfollow yourself!')
return redirect(url_for('user', nickname=nickname))
u = g.user.unfollow(user)
if u is None:
flash('Cannot unfollow ' + nickname + '.')
return redirect(url_for('user', nickname=nickname))
db.session.add(u)
db.session.commit()
flash('You have stopped following ' + nickname + '.')
return redirect(url_for('user', nickname=nickname))
这里应该不需要做过多的解释,但是需要注意的是检查周围的错误,为了防止期望之外的错误,试着给用户提供信息并且重定向到合适的位置当错误发生的时候。
最后需要修改下模版(文件 app/templates/user.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<table>
<tr valign="top">
<td><img src="{{user.avatar(128)}}"></td>
<td>
<h1>User: {{user.nickname}}</h1>
{% if user.about_me %}<p>{{user.about_me}}</p>{% endif %}
{% if user.last_seen %}<p><i>Last seen on: {{user.last_seen}}</i></p>{% endif %}
<p>{{user.followers.count()}} followers |
{% if user.id == g.user.id %}
<a href="{{url_for('edit')}}">Edit your profile</a>
{% elif not g.user.is_following(user) %}
<a href="{{url_for('follow', nickname = user.nickname)}}">Follow</a>
{% else %}
<a href="{{url_for('unfollow', nickname = user.nickname)}}">Unfollow</a>
{% endif %}
</p>
</td>
</tr>
</table>
<hr>
{% for post in posts %}
{% include 'post.html' %}
{% endfor %}
{% endblock %}
在编辑一行上,我们会显示关注者的用户数目,后面可能会跟随三种可能的链接:
- 如果用户属于登录状态,“编辑” 链接会显示。
- 否则,如果用户不是关注者,“关注” 链接会显示。
- 否则,一个 “取消关注” 将会显示。
这个时候你可以运行应用程序,创建一些用户,试试关注以及取消关注用户。
最后剩下的就是 index 页,但是现在还不是完成的时候,我们会在下一章完成它。
分页¶
回顾¶
在前面的章节(关注者,联系人和好友),我们已经完成了所有支持 “关注者” 功能的数据库的修改。今天我们将会让我们应用程序接受用户的真实数据。我们将要告别伪造数据的时候!
我们接下来讲述的正是我们上一章离开的地方,所以你可能要确保应用程序 microblog 正确地安装和工作。
提交博客文章¶
让我们先以简单的内容开始,主页应该有一个提交新的 blog 的表单。
首先我们定义一个单字段的表单对象(文件 app/forms.py):
class PostForm(Form):
post = StringField('post', validators=[DataRequired()])
接着,我们把表单添加到模板中(文件 app/templates/index.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<h1>Hi, {{g.user.nickname}}!</h1>
<form action="" method="post" name="post">
{{form.hidden_tag()}}
<table>
<tr>
<td>Say something:</td>
<td>{{ form.post(size = 30, maxlength = 140) }}</td>
<td>
{% for error in form.errors.post %}
<span style="color: red;">[{{error}}]</span><br>
{% endfor %}
</td>
</tr>
<tr>
<td></td>
<td><input type="submit" value="Post!"></td>
<td></td>
</tr>
</table>
</form>
{% for post in posts %}
<p>
{{post.author.nickname}} says: <b>{{post.body}}</b>
</p>
{% endfor %}
{% endblock %}
到目前为止,内容没有什么解释的,都不是新的东西。我们只是简单的添加另外一个表单而已,跟我们之前做的一样。
最后,把这一切联系起来的视图函数需要被扩展用来处理表单(文件 app/views.py):
from forms import LoginForm, EditForm, PostForm
from models import User, Post
@app.route('/', methods=['GET', 'POST'])
@app.route('/index', methods=['GET', 'POST'])
@login_required
def index():
form = PostForm()
if form.validate_on_submit():
post = Post(body=form.post.data, timestamp=datetime.utcnow(), author=g.user)
db.session.add(post)
db.session.commit()
flash('Your post is now live!')
return redirect(url_for('index'))
posts = [
{
'author': {'nickname': 'John'},
'body': 'Beautiful day in Portland!'
},
{
'author': {'nickname': 'Susan'},
'body': 'The Avengers movie was so cool!'
}
]
return render_template('index.html',
title='Home',
form=form,
posts=posts)
让我们一个一个来回顾下这个函数的修改点:
- 导入 Post 和 PostForm 类
- 在与 index 视图函数相关联的两个路由上,我们接受 POST 请求,因为我们需要接受提交的 blog。
- 当接受常规的 GET 请求的时候我们像以前一样的处理。当我们接收到一个表单的提交的时候,我们在数据库中插入一个新的 Post 记录。
- 模板现在接受一个新的参数:form。
当我们在数据库中插入一个新的 Post 后,我们将会重定向到首页:
return redirect(url_for('index'))
我们这里可以轻松地跳过(不使用)重定向,允许函数继续到渲染模板的部分,这将会是更加高效的。因此,为什么需要重定向?考虑如果一个用户正在撰写 blog,接着不小心按到了浏览器的刷新键,会发生些什么。刷新的命令将会做些什么?浏览器将会重新发送上一次的请求作为刷新命令的结果。
没有重定向,上一次的请求是提交表单的 POST 请求,因此刷新动作将会重新提交表单,导致与第一个相同的第二个 Post 记录被写入数据库。这并不好。
有了重定向,我们迫使浏览器在表单提交后发送另外一个请求,即重定向页的请求。这是一个简单的 GET 请求,因此一个刷新动作将会重复 GET 请求而不是多次提交表单。
这个小技巧避免了用户在提交 blog 后不小心触发刷新的动作而导致插入重复的 blog。
显示 blog¶
我们将要从数据库获取 blog,并展示它们。
如果你还记得前几篇文章中,我们创建了几个伪造的 blog,它们已经在我们主页上展示很长一段时间。在 index 视图函数这两个创建的伪造的对象是简单的 Python 列表:
posts = [
{
'author': { 'nickname': 'John' },
'body': 'Beautiful day in Portland!'
},
{
'author': { 'nickname': 'Susan' },
'body': 'The Avengers movie was so cool!'
}
]
但是在上一章中我们已经创建了一个查询,它允许我们获取关注的用户的所有的 blog,因此我们简单地替换上面这些伪造的数据(文件 app/views.py):
posts = g.user.followed_posts().all()
当你运行应用程序的时候就会看到来自数据库中的 blog。
User 类中的 followed_posts 方法返回一个 sqlalchemy 查询对象,该查询对象用于获取我们感兴趣的 blog。在这个查询中调用 all() 只是为了检索所有的 blog 并形成一个列表,因此我们以一个与我们使用的伪造数据相似的结构结束。模版是不会注意到这一点的。
这个时候可以接着试试你的应用程序了。你可以创建一些用户,接着关注他们(她们),最后发布些 blog。
分页¶
应用程序看起来比任何时候都要好,但是还是有个问题。我们把所有关注者的 blog 展示在首页上。如果数量超过上千的话会发生些什么?或者上百万?你可以想象得到,处理如此大数据量的列表对象将会及其低效的。
相反,如果我们分组或者分页显示大量的 blog?效率和效果会不会好一些了?
Flask-SQLAlchemy 天生就支持分页。比如如果我们想要得到用户关注者的前三篇 blog,我们可以这样做:
posts = g.user.followed_posts().paginate(1, 3, False).items
paginate 方法能够被任何查询调用。它接受三个参数:
- 页数,从 1 开始,
- 每一页的项目数,这里也就是说每一页显示的 blog 数,
- 错误标志。如果是 True,当请求的范围页超出范围的话,一个 404 错误将会自动地返回到客户端的网页浏览器。如果是 False,返回一个空列表而不是错误。
从 paginate 返回的值是一个 Pagination 对象。这个对象的 items 成员包含了请求页面项目(本文是指 blog)的列表。在 Pagination 对象中还有其它有帮助的东西,我们将在后面能看到。
现在让我们想想如何在我们的 index 视图函数中实现分页。我们首先在配置文件中添加一些决定每页显示的 blog 数的配置项(文件 config.py):
# pagination
POSTS_PER_PAGE = 3
在最后的应用程序中我们当然会使用每页显示的 blog 数大于 3,但是测试的时候用小的数量更加方便。
接着,让我们看看不同页的 URLs 是什么样的。我们知道 Flask 路由可以携带参数,因此我们在 URL 后添加一个后缀表示所需的页面:
http://localhost:5000/ <-- page #1 (default)
http://localhost:5000/index <-- page #1 (default)
http://localhost:5000/index/1 <-- page #1
http://localhost:5000/index/2 <-- page #2
这种格式的 URLs 能够轻易地通过在我们的视图函数中附加一个 route 来实现(文件 app/views.py):
from config import POSTS_PER_PAGE
@app.route('/', methods = ['GET', 'POST'])
@app.route('/index', methods = ['GET', 'POST'])
@app.route('/index/<int:page>', methods = ['GET', 'POST'])
@login_required
def index(page = 1):
form = PostForm()
if form.validate_on_submit():
post = Post(body = form.post.data, timestamp = datetime.utcnow(), author = g.user)
db.session.add(post)
db.session.commit()
flash('Your post is now live!')
return redirect(url_for('index'))
posts = g.user.followed_posts().paginate(page, POSTS_PER_PAGE, False).items
return render_template('index.html',
title = 'Home',
form = form,
posts = posts)
我们新的路由需要页面数作为参数,并且声明为一个整型。同样我们也需要在 index 函数中添加 page 参数,并且我们需要给它一个默认值。
现在我们已经有可用的页面数,我们能够很容易地把它与配置中的 POSTS_PER_PAGE 一起传入 followed_posts 查询。
现在试试输入不同的 URLs,看看分页的效果。但是,需要确保可用的 blog 数要超过三个,这样你就能够看到不止一页了!
页面导航¶
我们现在需要添加链接允许用户访问下一页以及/或者前一页,幸好这是很容易做的,Flask-SQLAlchemy 为我们做了大部分工作。
我们现在开始在视图函数中做一些小改变。在我们目前的版本中我们按如下方式使用 paginate 方法:
posts = g.user.followed_posts().paginate(page, POSTS_PER_PAGE, False).items
通过上面这样做,我们可以获得返回自 paginate 的 Pagination 对象的 items 成员。但是这个对象还有很多其它有用的东西在里面,因此我们还是使用整个对象(文件 app/views.py):
posts = g.user.followed_posts().paginate(page, POSTS_PER_PAGE, False)
为了适应这种改变,我们必须修改模板(文件 app/templates/index.html):
<!-- posts is a Paginate object -->
{% for post in posts.items %}
<p>
{{post.author.nickname}} says: <b>{{post.body}}</b>
</p>
{% endfor %}
这个改变使得模版能够使用完全的 Paginate 对象。我们使用的这个对象的成员有:
- has_next:如果在目前页后至少还有一页的话,返回 True
- has_prev:如果在目前页之前至少还有一页的话,返回 True
- next_num:下一页的页面数
- prev_num:前一页的页面数
有了这些元素后,我们产生了这些(文件 app/templates/index.html):
<!-- posts is a Paginate object -->
{% for post in posts.items %}
<p>
{{post.author.nickname}} says: <b>{{post.body}}</b>
</p>
{% endfor %}
{% if posts.has_prev %}<a href="{{ url_for('index', page = posts.prev_num) }}"><< Newer posts</a>{% else %}<< Newer posts{% endif %} |
{% if posts.has_next %}<a href="{{ url_for('index', page = posts.next_num) }}">Older posts >></a>{% else %}Older posts >>{% endif %}
因此,我们有了两个链接。第一个就是名为 “Newer posts”,这个链接使得我们能够访问上一页。第二个就是 “Older posts”,它指向下一页。
当我们浏览第一页的时候,我们不希望看到有上一页的链接,因为这时候是不存在前一页。这是很容易被监测的,因为 posts.has_prev 会是 False。我们简单地处理这种情况,当用户浏览首页的时候,上一页会显示出来,但是不会有任何的链接。同样,下一页也是这样的处理方式。
实现 Post 子模板¶
在前面的章节中,我们定义了一个子模板来渲染单个 blog。定义这个子模板的原因是在多个使用单个 blog 的页面的时候只需要包含这个子模板就行了,不需要重复拷贝 HTML 代码。
现在是时候在我们的首页上也包含这个子模板。大部分的事情都已经做完了,因此这是很简单的(文件 app/templates/index.html):
<!-- posts is a Paginate object -->
{% for post in posts.items %}
{% include 'post.html' %}
{% endfor %}
惊人吧?我们只是丢弃旧的渲染代码,取而代之的是一个包含子模板新的 HTML 代码。就只做了这一点,我们得到更好的版本。
下面是目前应用程序的截图:
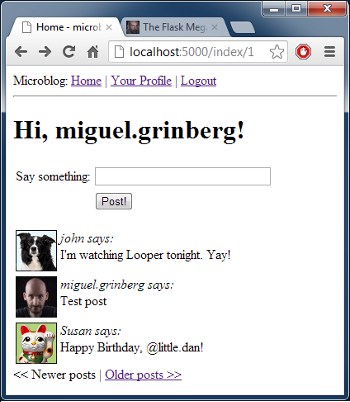
用户信息页¶
首页上的分页已经完成了。然而,我们在用户信息页上显示了 blog。为了保持一致性,用户信息页也跟首页一样。
改变是跟修改首页一样的。这是我们需要做的列表:
- 添加一个额外的路由获取页面数的参数
- 添加一个默认值为 1 的 page 参数到视图函数
- 用合适的数据库查询与分页代替伪造的 blog
- 更新模板使用分页对象
下面就是更新后的视图函数(文件 app/views.py):
@app.route('/user/<nickname>')
@app.route('/user/<nickname>/<int:page>')
@login_required
def user(nickname, page=1):
user = User.query.filter_by(nickname=nickname).first()
if user is None:
flash('User %s not found.' % nickname)
return redirect(url_for('index'))
posts = user.posts.paginate(page, POSTS_PER_PAGE, False)
return render_template('user.html',
user=user,
posts=posts)
注意上面的视图函数已经有一个 nickname 参数,我们把 page 作为它的第二个参数。
模版的改变同样很简单(文件 app/templates/user.html):
<!-- posts is a Paginate object -->
{% for post in posts.items %}
{% include 'post.html' %}
{% endfor %}
{% if posts.has_prev %}<a href="{{ url_for('user', nickname = user.nickname, page = posts.prev_num) }}"><< Newer posts</a>{% else %}<< Newer posts{% endif %} |
{% if posts.has_next %}<a href="{{ url_for('user', nickname = user.nickname, page = posts.next_num) }}">Older posts >></a>{% else %}Older posts >>{% endif %}
全文搜索¶
回顾¶
在前面的章节(分页),我们已经加强了数据库查询,因此能够在页面上获取各种查询。
今天,我们会继续探讨数据库的话题,只是领域不同。所有存储内容的应用程序必须提供搜索能力。
许多其它类型的网站可能使用了谷歌、必应等索引所有的内容并且提供查询结果。这个对于大多数静态页面的网站,像论坛,是很好用。我们应用程序 microblog 的基本单元是用户短小的 blog,不是整个页面。我们希望搜索结果是动态的。例如,我们想要在所有的 blog 中搜索关键词 “dog”。这是显而易见的,除非是有人搜索这个词,不然大型的搜索引擎不可能索引搜索结果。因此我们除了使用自己的搜索是别无选择的。
全文搜索引擎的简介¶
不幸的是,在关系数据库中的全文搜索支持没有得到很好的规范。每个数据库都以自己的方式实现全文搜索,并且 SQLAlchemy 没有实现全文搜索。
我们目前使用了 SQLite 作为数据库,因此我们可以绕过 SQLAlchemy,使用 SQLite 提供的特性来创建全文文本索引。但是这并不是一个好主意,因为如果我们要更换数据库的时候,我们需要重写全文搜索的代码。
因此,相反我们让数据库处理常规数据,我们将创建一个专门的数据库,专注服务于文本搜索。
现在有一些开源的全文搜索引擎。在我的知识范围内唯一一个用 Python 编写的 Flask 扩展是 Whoosh。一个纯 Python 的搜索引擎的好处就是在 Python 解释器可用的任何地方能够安装和运行。缺点也是很显然的,性能可能比不上 C 或者 C++ 编写的。我的观点是最理想的解决方式就是开发一个连接不同搜索引擎的 Flask 扩展,以某种方式来处理搜索,就像 Flask-SQLAlchemy 一样。但是目前在 Flask 中暂时没有这类型的扩展。Django 开发者提供了一个很好的扩展,用来支持不同的全文搜索引擎,叫做 django-haystack。也许不久就会有人写一个类似的 Flask 扩展。
如果你暂时没有在虚拟环境上安装 Flask-WhooshAlchemy,请安装它。Windows 用户应该运行这个:
flask\Scripts\pip install Flask-WhooshAlchemy
其它用户必须运行这个:
flask/bin/pip install Flask-WhooshAlchemy
Python 3 兼容性¶
非常不幸地是,Flask-WhooshAlchemy 这个包在 Python 3 中存在问题。并且 Flask-WhooshAlchemy 不会兼容 Python 3。我为这个扩展做了一个分支并且做了一些改变以便其兼容 Python 3,因此你们需要卸载官方的版本并且安装我的分支:
$ flask/bin/pip uninstall flask-whooshalchemy
$ flask/bin/pip install git+git://github.com/miguelgrinberg/flask-whooshalchemy.git
令人遗憾地这不是唯一的问题。Whoosh 同样与 Python 3 的兼容存在问题。我在测试中遇到过 这个问题 <https://bitbucket.org/mchaput/whoosh/issue/395/ascii-codec-error-when-performing-query>,但是以我的能力目前也无法解决这个问题,只能等待官方的修复。目前来说,Python 3 暂时不能完全地使用这个功能。
配置¶
配置 Flask-WhooshAlchemy 也是相当简单。我们只需要告诉扩展全文搜索数据库的名称(文件 config.py):
WHOOSH_BASE = os.path.join(basedir, 'search.db')
模型修改¶
因为把 Flask-WhooshAlchemy 整合进 Flask-SQLAlchemy,我们需要在模型的类中指明哪些数据需要建立搜索索引(文件 app/models.py):
from app import app
import sys
if sys.version_info >= (3, 0):
enable_search = False
else:
enable_search = True
import flask.ext.whooshalchemy as whooshalchemy
class Post(db.Model):
__searchable__ = ['body']
id = db.Column(db.Integer, primary_key=True)
body = db.Column(db.String(140))
timestamp = db.Column(db.DateTime)
user_id = db.Column(db.Integer, db.ForeignKey('user.id'))
def __repr__(self):
return '<Post %r>' % (self.body)
if enable_search:
whooshalchemy.whoosh_index(app, Post)
模型有一个新的 __searchable__ 字段,这里面包含数据库中的所有能被搜索并且建立索引的字段。在我们的例子中,我们只要索引 blog 的 body 字段。
通过调用 whoosh_index 函数,我们为这个模型初始化了全文搜索索引。
因为这个改变并不影响到关系数据库的格式,因此不需要录制新的迁移脚本。
因为之前存储在数据库的 blog 是没有建立索引的。为了保持数据库和全文搜索引擎的同步,我们需要删除之前撰写的 blog:
>>> from app.models import Post
>>> from app import db
>>> for post in Post.query.all():
... db.session.delete(post)
>>> db.session.commit()
搜索¶
现在我们准备开始搜索。首先让我们在数据库中添加些 blog。有两种方式去添加。我们可以运行应用程序,通过浏览器像普通用户一样添加 blog。另外一种就是在 Python 提示符下。
在 Python 提示符下,我们可以按如下的去做:
>>> from app.models import User, Post
>>> from app import db
>>> import datetime
>>> u = User.query.get(1)
>>> p = Post(body='my first post', timestamp=datetime.datetime.utcnow(), author=u)
>>> db.session.add(p)
>>> p = Post(body='my second post', timestamp=datetime.datetime.utcnow(), author=u)
>>> db.session.add(p)
>>> p = Post(body='my third and last post', timestamp=datetime.datetime.utcnow(), author=u)
>>> db.session.add(p)
>>> db.session.commit()
现在我们在全文索引中有一些 blog,我们可以这样搜索:
>>> Post.query.whoosh_search('post').all()
[<Post u'my second post'>, <Post u'my first post'>, <Post u'my third and last post'>]
>>> Post.query.whoosh_search('second').all()
[<Post u'my second post'>]
>>> Post.query.whoosh_search('second OR last').all()
[<Post u'my second post'>, <Post u'my third and last post'>]
在上面例子中你可以看到,查询并不限制于单个词。实际上,Whoosh 支持一个更加强大的 搜索查询语言。
整合全文搜索到应用程序¶
为了使得搜索功能在我们的应用程序中可用,我们需要添加些修改。
搜索表单¶
我们准备在导航栏中添加一个搜索表单。把表单放在导航栏中是有好处的,因为应用程序所有页都有搜索表单。
首先,我们添加一个搜索表单类(文件 app/forms.py):
class SearchForm(Form):
search = StringField('search', validators=[DataRequired()])
接着我们必须创建一个搜索表单对象并且使得它对所有模版中可用,因为我们将搜索表单放在导航栏中,导航栏是所有页面共有的。最容易的方式就是在 before_request 函数中创建这个表单对象,接着把它放在全局变量 g 中(文件 app/views.py):
from forms import SearchForm
@app.before_request
def before_request():
g.user = current_user
if g.user.is_authenticated():
g.user.last_seen = datetime.utcnow()
db.session.add(g.user)
db.session.commit()
g.search_form = SearchForm()
我们接着添加表单到模板中(文件 app/templates/base.html):
<div>Microblog:
<a href="{{ url_for('index') }}">Home</a>
{% if g.user.is_authenticated() %}
| <a href="{{ url_for('user', nickname = g.user.nickname) }}">Your Profile</a>
| <form style="display: inline;" action="{{url_for('search')}}" method="post" name="search">{{g.search_form.hidden_tag()}}{{g.search_form.search(size=20)}}<input type="submit" value="Search"></form>
| <a href="{{ url_for('logout') }}">Logout</a>
{% endif %}
</div>
注意,只有当用户登录后,我们才会显示搜索表单。before_request 函数仅仅当用户登录才会创建一个表单对象,因为我们的程序不会对非认证用户显示任何内容。
搜索视图函数¶
上面的模版中,我们在 action 字段中设置发送搜索请求到 search 视图函数。search 视图函数如下(文件 app/views.py):
@app.route('/search', methods = ['POST'])
@login_required
def search():
if not g.search_form.validate_on_submit():
return redirect(url_for('index'))
return redirect(url_for('search_results', query = g.search_form.search.data))
这个函数实际做的事情不多,它只是从查询表单这能够获取查询的内容,并把它作为参数重定向另外一页。搜索工作不在这里直接做的原因还是担心用户无意中触发了刷新,这样会导致表单数据被重复提交。
搜索结果页¶
一旦查询的关键字被接收到,search_results 函数就会开始工作(文件 app/views.py):
from config import MAX_SEARCH_RESULTS
@app.route('/search_results/<query>')
@login_required
def search_results(query):
results = Post.query.whoosh_search(query, MAX_SEARCH_RESULTS).all()
return render_template('search_results.html',
query = query,
results = results)
搜索结果视图函数把查询传递给 Whoosh,并且把最大的结果数也作为参数传递给 Whoosh。
最后一部分就是搜索结果的模版(文件 app/templates/search_results.html):
<!-- extend base layout -->
{% extends "base.html" %}
{% block content %}
<h1>Search results for "{{query}}":</h1>
{% for post in results %}
{% include 'post.html' %}
{% endfor %}
{% endblock %}
邮件支持¶
回顾¶
在近来的几篇教程中,我们一直在与数据库打交道。
今天我们打算让数据库休息下,相反我们今天准备完成网页应用程序中一项重要的功能:能够给用户发送邮件。
在我们小型 microblog 应用程序,我们将要实现一个与邮件有关的功能,我们将会给用户发送一封邮件当他或者她被人关注的时候。实现邮件有很多方式,因此我们需要设计一个通用的框架,以便重用。
安装 Flask-Mail¶
幸运地,Flask 已经存在处理邮件的扩展,尽管不是 100% 支持我们想要的功能,但是已经很好了。
在我们的虚拟环境上安装 Flask-Mail 是相当简单的。在 Windows 以外的其它系统上的用户可以按照如下命令:
flask/bin/pip install flask-mail
Windows 上的用户稍微有些不同,因为 Flask-Mail 中使用的一个模块不支持该系统,用户需要按照如下命令:
flask\Scripts\pip install --no-deps lamson chardet flask-mail
配置¶
当我们在 单元测试 中,已经为了能够发送错误信息。配置了邮件相关的信息,实际上它也能用于发送用户相关的邮件。
作为提醒,我必须重复下配置中需要的信息:
- 用于发送邮件的邮件服务器
- 管理员的邮箱地址
下面就是 单元测试 中的配置(文件 config.py):
# email server
MAIL_SERVER = 'your.mailserver.com'
MAIL_PORT = 25
MAIL_USERNAME = None
MAIL_PASSWORD = None
# administrator list
ADMINS = ['[email protected]']
在开始发送应用程序的邮件之前,我们必须输入实际的邮件服务器以及管理员的邮箱。比如,如果你想要应用程序通过你的 gmail 账号发送邮件,你可以输入如下内容:
# email server
MAIL_SERVER = 'smtp.googlemail.com'
MAIL_PORT = 465
MAIL_USE_TLS = False
MAIL_USE_SSL = True
MAIL_USERNAME = os.environ.get('MAIL_USERNAME')
MAIL_PASSWORD = os.environ.get('MAIL_PASSWORD')
# administrator list
ADMINS = ['[email protected]']
我们也需要初始化一个 Mail 对象,这个对象为我们连接到 SMTP 服务器并且发送邮件(文件 app/__init__.py):
from flask.ext.mail import Mail
mail = Mail(app)
让我们发送邮件!¶
为了学习 Flask-Mail 是如何工作的,我们将会在命令行中发送邮件。因此让我们在虚拟环境中启动 Python并且执行下面的代码:
>>> from flask.ext.mail import Message
>>> from app import app, mail
>>> from config import ADMINS
>>> msg = Message('test subject', sender = ADMINS[0], recipients = ADMINS)
>>> msg.body = 'text body'
>>> msg.html = '<b>HTML</b> body'
>>> with app.app_context():
... mail.send(msg)
....
上面的代码块将会向在配置 config.py 中的管理员列表所有成员发送邮件。发送者是管理员列表中的第一个管理员。邮件有文本和 HTML 版本,这取决你邮件客户端的设置。注意我们需要创建一个 app_context 来发送邮件。Flask-Mail 最近的版本需要这个。当 Flask 处理请求的时候,应用内容就被自动地创建。因为我们不是在请求中,必须手动地创建内容。
好了,是时候把代码整合进我们的应用程序了。
简单的邮件框架¶
我们现在编写一个辅助方法用于发送邮件。这是上面使用的测试代码通用的版本。我们将会把这个函数放入一个新文件,专门用于我们的应用程序的邮件支持(文件 app/emails.py):
from flask.ext.mail import Message
from app import mail
def send_email(subject, sender, recipients, text_body, html_body):
msg = Message(subject, sender = sender, recipients = recipients)
msg.body = text_body
msg.html = html_body
mail.send(msg)
Flask-Mail 支持的应用超出了我们所用的。比如,抄送以及附件也是可用的,但是我们不准备在应用程序中使用。
关注提醒¶
现在我们已经有了发送邮件的基本框架,我们可以编写发送关注提醒的函数(文件 app/emails.py):
from flask import render_template
from config import ADMINS
def follower_notification(followed, follower):
send_email("[microblog] %s is now following you!" % follower.nickname,
ADMINS[0],
[followed.email],
render_template("follower_email.txt",
user = followed, follower = follower),
render_template("follower_email.html",
user = followed, follower = follower))
也许你会感到很惊奇。我们的老朋友 render_template 居然出现在这里。如果你还记得,我们用此函数来渲染视图中所有的 HTML 模板。像视图中的模板一样,邮件的主体也是使用模板的理想候选者。
因此我们需要编写我们的关注者提醒邮件的文本以及 HTML 版本的模板。这里是文本版本(文件 app/templates/follower_email.txt):
Dear {{user.nickname}},
{{follower.nickname}} is now a follower. Click on the following link to visit {{follower.nickname}}'s profile page:
{{url_for("user", nickname = follower.nickname, _external = True)}}
Regards,
The microblog admin
对于 HTML 版本,我们可能会做得更好些,甚至会显示出关注者的头像和用户信息(文件 app/templates/follower_email.html):
<p>Dear {{user.nickname}},</p>
<p><a href="{{url_for("user", nickname = follower.nickname, _external = True)}}">{{follower.nickname}}</a> is now a follower.</p>
<table>
<tr valign="top">
<td><img src="{{follower.avatar(50)}}"></td>
<td>
<a href="{{url_for('user', nickname = follower.nickname, _external = True)}}">{{follower.nickname}}</a><br />
{{follower.about_me}}
</td>
</tr>
</table>
<p>Regards,</p>
<p>The <code>microblog</code> admin</p>
注意在上面模板中的 url_for 有 _external = True 参数。默认情况下,url_for 函数生成的 URLs 是与当前页面的域名相关的。例如,url_for(“index”) 返回值将会是 /index,但是在实际视图函数中返回的是 http://localhost:5000/index。在邮件中是不存在域名的内容,因此我们必须要生成完全的包含域名的 URLs,_external 参数就是为这个目的。
最后一步就是把发送邮件整合到实际的视图函数中(文件 app/views.py):
from emails import follower_notification
@app.route('/follow/<nickname>')
@login_required
def follow(nickname):
user = User.query.filter_by(nickname = nickname).first()
# ...
follower_notification(user, g.user)
return redirect(url_for('user', nickname = nickname))
现在您可以创建两个账户并且让一个用户关注另外一个用户,看看邮件提醒是如何工作的。
这就足够了吗?¶
邮件提醒的工作已经完成了,但是是不是已经足够了?会不会存在一些问题了?
随着你不断地使用关注的链接,你可能会发现当你点击 follow 链接的时候,浏览器需要等到 2 到 3 秒的时间刷新页面,尽管邮件是正常地收到了。以前这可是瞬间完成的。
这是怎么回事了?
问题就是 Flask-Mail 发送邮件是同步的。网页服务器是被阻塞了当发送邮件的时候,直到邮件已交付响应返回给浏览器。想象下,如果当我们试图发送邮件的时候,邮件服务器是很慢,或者甚至更差,临时断线,会发生些什么?这个解决方案并不完美。
这已经成为了应用程序的一个瓶颈了,发送邮件应该是一个不会干扰到网页服务器的后台程序,所以让我们看看如何解决这个问题。
在 Python 中异步调用¶
我们真正想要的就是 send_email 函数立即返回,发送邮件的工作移到后台处理。
事实上 Python 已经支持运行异步任务,而且有不止一种方式。threading 以及 multiprocessing 模块都可以达到这个目的。
每次我们需要发送邮件的时候启动一个进程的资源远远小于启动一个新的发送邮件的整个过程,因此把 mail.send(msg) 调用移入线程中(文件 app/emails.py):
from threading import Thread
from app import app
def send_async_email(app, msg):
with app.app_context():
mail.send(msg)
def send_email(subject, sender, recipients, text_body, html_body):
msg = Message(subject, sender=sender, recipients=recipients)
msg.body = text_body
msg.html = html_body
thr = Thread(target=send_async_email, args=[app, msg])
thr.start()
如果现在测试点击 follow 链接后的速度的话,浏览器会瞬间刷新页面了。
既然异步的邮件发送功能已经实现了,如果将来我们需要实现其它异步的函数,还有什么需要改进的吗?我们需要为每一个实现异步功能的函数拷贝多线程的代码吗?这并不好。
我们可以通过实现一个 装饰器 来解决这个问题。有了装饰器,上面的代码可以修改为:
from .decorators import async
@async
def send_async_email(app, msg):
with app.app_context():
mail.send(msg)
def send_email(subject, sender, recipients, text_body, html_body):
msg = Message(subject, sender=sender, recipients=recipients)
msg.body = text_body
msg.html = html_body
send_async_email(app, msg)
好的多了吧,对不对?
这个神奇的代码其实很简单。我们把它放入一个新文件(文件 app/decorators.py):
from threading import Thread
def async(f):
def wrapper(*args, **kwargs):
thr = Thread(target = f, args = args, kwargs = kwargs)
thr.start()
return wrapper
而现在我们间接为异步任务创建了一个有用的框架,我们可以说我们已经完成了!
作为一个练习,大家可以考虑考虑如何用 multiprocessing 模块来实现上面的功能。
换装¶
简介¶
如果你一直追随着 microblog 应用程序,你可能发现我们并没有在应用程序的外观上花很多的时间。到目前为止,我们使用的模板是基本的,并且没有风格而言。这也是有帮助的,当我们编码的时候,我们不想为编写好看的 HTML 而分心。
这篇文章将会与以前的有所不同,因为写好看的 HTML/CSS 是一个巨大的话题,超出这一系列的预期范围。这里不会有任何 HTML 或 CSS 的细节,我们将只讨论基本的指导方针和思路。
我们该怎么做?¶
虽然我们可以认为编码是很难的,但是这些痛苦比不上那些网页设计师,他们必须编写好的并且具有一致性的模板以适应各种浏览器。在如今的社会中,他们不仅仅需要使得设计在常规的浏览器上看起来不错,并且还需要在平板电脑、智能手机上的浏览器上显得好看。
不幸地是,学习 HTML, CSS 以及 Javascript,并且清楚它们在每一种浏览器上的特性是一个深不见底的任务。我们不可能有很多的时间去做。我们只希望少投入些精力让我们的应用程序好看。
因此怎么样才能在这么多限制下完成我们的 microblog 界面?
Bootstrap 简介¶
我们在 Twitter 里的好朋友发布了一个开源 web 框架,叫做 Bootstrap,它可能就是我们的救命稻草。
Bootstrap 是最常见的网页类型的 CSS 和 Javascript 工具的集合。如果你想要看用这个框架设计的网页,请看这些 例子。
Bootstrap 擅长如下这些东西:
- 在所有的主流浏览器上看起来一样
- 台式机,平板电脑和手机的屏幕大小不一的处理
- 可定制的布局
- 多风格的导航栏
- 多风格的表单
- 其它很多,很多...
用 Bootstrap 装点 microblog¶
在我们把 Bootstrap 添加到应用程序之前,我们必须安装 Bootstrap CSS,Javascript 以及 图片文件到我们的网页服务器可以找到的地方。
在 Flask 中,app/static 文件夹就是这些常规文件所在地。当一个 URL 中有一个 /static 后缀的话,网页服务器就知道到这个文件夹中寻找文件。
例如,如果我们存储一个名为 image.png 文件在 /app/static 中,我们能够在模板中显示带有如下标签的图片:
<img src="/static/image.png" />
我们将会根据如下结构来安装 Bootstrap 框架:
/app
/static
/css
bootstrap.min.css
bootstrap-responsive.min.css
/img
glyphicons-halflings.png
glyphicons-halflings-white.png
/js
bootstrap.min.js
根据 说明 ,我们必须在基础模板中的 head 部分加入如下内容:
<!DOCTYPE html>
<html lang="en">
<head>
...
<link href="/static/css/bootstrap.min.css" rel="stylesheet" media="screen">
<link href="/static/css/bootstrap-responsive.min.css" rel="stylesheet">
<script src="http://code.jquery.com/jquery-latest.js"></script>
<script src="/static/js/bootstrap.min.js"></script>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
...
</head>
...
</html>
接下来我们需要对模板做的改变有:
- 整个页面的内容使用 固定的布局 与 响应功能
- 使用 Bootstrap 的 表单形式 替换所有的表单
- 使用 导航 替换我们的导航栏
- 用 分页 按钮 改变 上一页以及下一页的链接
- 为闪现消息使用 Bootstrap 的 警告样式
- 使用 样式图片 来表示登录表单中的推荐的 OpenID 提供商
我们不会详细解释每一个变化了,因为这些是相当简单。Bootstrap 官方文档 会对大家很有帮助的。
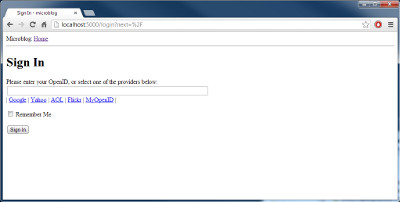
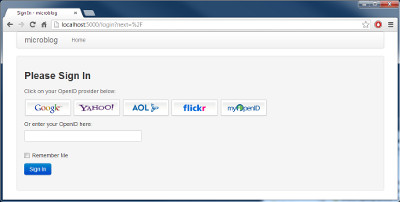
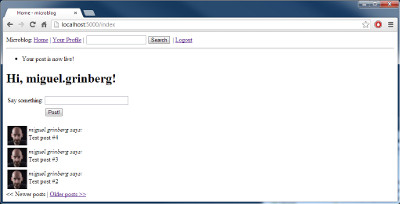
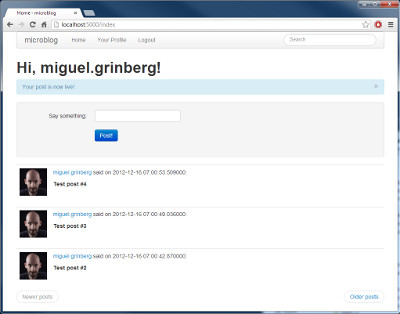
日期和时间¶
善意提醒¶
对于那些还没有注意到的读者,近来项目已经迁移到 github 上,你们可以在这个位置找到代码: https://github.com/miguelgrinberg/microblog。
我已经添加了标签指向每个教程步骤,为您提供便利。
时间戳的问题¶
我们 microblog 应用程序已经忽略很长时间的一个方面就是时间和日期的显示。
到目前为止,我们信任 Python 本身去渲染在我们 User 和 Post 对象中的 datetime 对象,然而这真不是一个好的解决方案。
考虑如下的例子。我在 2012.12.31 的下午 3:54 写的这篇文章。我的时区是 PST (或者 UTC-8 如果你更喜欢的话)。在 Python 解释器运行能得到如下信息:
>>> from datetime import datetime
>>> now = datetime.now()
>>> print now
2012-12-31 15:54:42.915204
>>> now = datetime.utcnow()
>>> print now
2012-12-31 23:55:13.635874
now() 调用返回本地时区的正确的时间,然而 utcnow() 调用返回 UTC 单位的时间。
因此用哪个更好?
如果我们所有的时间戳都使用 now(),我们将会在数据库中存储服务器运行本地的时间,然而这会带来一些问题。
有一天我们想把服务器迁移到不同时区的地方,那么所有数据库中的时间戳必须修改成当地的正确时间在服务器重启之前。
但是这还有一个更重要的问题。对于不同时区的用户很难清楚知道 blog 的发布时间因为他们看到的是在 PST 时区的时间。他们需要提前知道服务器的时区是 PST 才能做出适当的调整。
显然,这不是一个好的选择,这是为什么开始使用我们的数据库的时候,我们决定我们总是以 UTC 时区存储时间戳。
尽管用 UCT 时区标准化了时间戳解决了迁移服务器的问题。但是它解决不了第二个问题,日期和时间在世界上的任何地方都会以 UTC 形式呈献给用户。
这也是很令人困惑的。想象下一个在 PST 时区的用户在下午 3:00 发布一篇 blog,结果首页显示的时间是下午 11:00 或者是 23:00。用户会不会感到很奇怪啊?
今天,文章的目的是解决日期和时间显示的问题,使得我们的用户不要混淆。
用户特定的时间戳¶
最明显解决问题的方案就是为每一个用户单独把时间戳从 UTC 转换到当地时区。这也允许我们接着在数据库中使用 UTC 时区。
但是如何知道每一个用户的当地时区了?
许多网页都会有一个配置页,用户可以指定当地时区。这就需要我们添加一个新页,新页上需要一个表单,用户可以在表单上的下拉框中选择自己当地的时区。作为注册的一部分,用户第一次访问页面的时候,需要被要求输入他们的时区。
尽管这是一个比较好的解决方案,但是用户的系统配置中已经配置了时区,让用户输入这样的信息有些累赘。如果我们能获取用户电脑上的时区的话看起来更有效些。
出于安全原因,网页浏览器是不允许从用户的操作系统中获取信息。即使这是可能的话,我们需要在 Windows, Linux, Mac, iOS, 以及 Android 上(这还是没有统计其他类型的操作系统)去查询时区。
其实网页浏览器知道用户的时区,并且可以通过标准的 Javascript APIs 导出。在 Web 2.0 世界里,用户开启 Javascript 的假设是安全的(现代的网页没有脚本是不能工作的),因此这个方案是有潜力的。
我们有两种方式通过 Javascript 来利用可用的时区配置:
- “老派” 的方式就是让网页浏览器在某时候发送时区信息当用户第一次登录到服务器。这可以通过 Ajax 调用,或者 一个 刷新标记。一旦服务器知道了时区会把它保存到用户的会话中,当模板渲染的时候会去调整时间。
- “新派” 的方式就是不会在服务器上改变任何东西,会继续把 UTC 时间戳发送到客户端浏览器上。从 UTC 到当地时区的转换是通过 Javascript 在客户端实现的。
两种方式都不错,但是第二种更加不错。浏览器是最有能力根据系统时区配置来渲染时间的。最具有吸引力的是,第二种方式有现成的。
介绍 moment.js¶
Moment.js 是一个小型的,自由的,开源的 Javascript 库,它能够渲染日期和时间。它提供了富有想象的格式化选项。
为了在我们应用程序中使用 moment.js,我们需要在模板中写一点 Javascript。我们开始从 ISO 8601 时区构建一个 moment 对象。例如,我们可以创建一个 moment 对象像这样:
moment(“2012-12-31T23:55:13 Z”)
一旦对象被构建,它能够被渲染成各种格式的字符串。例如,根据系统时区进行详细的渲染:
moment("2012-12-31T23:55:13 Z").format('LLLL');
下面就是结果:
Tuesday, January 1 2013 7:55 AM
这里是一些不同格式渲染的效果:

除了提供了 format(),它还提供了 fromNow() 和 calendar():

请注意,在所有的例子中,服务器渲染相同的 UTC 时间,在自己的网页浏览器中执行不同的渲染。
我们现在缺少的就是让 moment 返回的字符串在页面上可见。实现这个最简单的方式就是 Javascript 的 document.write 函数:
<script>
document.write(moment("2012-12-31T23:55:13 Z").format('LLLL'));
</script>
整合 moment.js¶
在我们的应用程序中使用 moment.js 还需要做一些事情。
首先,把下载下来的 moment.min.js 放入到 /app/static/js 文件夹,这样它就能作为一个静态文件提供给客户端。
接着,在我们的基础模板中添加对这个库的引用(文件 app/templates/base.html):
<script src="/static/js/moment.min.js"></script>
我们现在在模板中添加 <script> 标签,用来显示时间戳。但是与这样方式不同的,我们将会创建一个 moment.js 封装,我们能在模版中调用这个封装。这会节省不少时间如果我们必须修改时间戳渲染代码,因为我们已经把它放在一个地方。
我们的封装是一个很简单的 Python 类(文件 app/momentjs.py):
from jinja2 import Markup
class momentjs(object):
def __init__(self, timestamp):
self.timestamp = timestamp
def render(self, format):
return Markup("<script>\ndocument.write(moment(\"%s\").%s);\n</script>" % (self.timestamp.strftime("%Y-%m-%dT%H:%M:%S Z"), format))
def format(self, fmt):
return self.render("format(\"%s\")" % fmt)
def calendar(self):
return self.render("calendar()")
def fromNow(self):
return self.render("fromNow()")
注意 render 方法并不直接返回字符串而是把它放入了 Jinja2 提供的 Markup 对象中。原因是 Jinja2 默认情况下会自动转义,例如,我们的 <script> 标签是不可能到达到客户端,因为转义成 <script>。把字符串包裹在 Markup 对象里就是告诉 Jinja2 这个字符串是不需要转义的。
既然我们有了一个封装的类,我们需要跟 Jinja2 绑定,这样模块就可以使用它(文件 app/__init__.py):
from momentjs import momentjs
app.jinja_env.globals['momentjs'] = momentjs
上面的代码就是告诉 Jinja2 导入我们的类作为所有模板的一个全局变量。
现在我们准备修改模版。在我们应用程序中有两个地方显示日期和时间。一个就是用户信息页,那里有最后一次登录时间。对于这个时间戳,我们将会使用 calendar() 格式(文件 app/templates/user.html):
{% if user.last_seen %}
<p><em>Last seen: {{momentjs(user.last_seen).calendar()}}</em></p>
{% endif %}
第二个地方就是在 post 子模板,它是被首页,用户信息页以及搜索页调用。在这里我们将会使用 fromNow() 格式,因为一篇 blog 的撰写时间和它离现在有多久了是一样重要的。我们需要修改子模板使得所有使用它的页面都有效(文件 app/templates/post.html):
<p><a href="{{url_for('user', nickname = post.author.nickname)}}">{{post.author.nickname}}</a> said {{momentjs(post.timestamp).fromNow()}}:</p>
<p><strong>{{post.body}}</strong></p>
做完这些修改后,我们解决了所有我们的时间戳问题。我们不需要对服务器代码做单个的修改!
结束语¶
不知不觉中我们已经做了很重要的一步,使得 microblog 让国际用户能够根据本地时区看到不同的日期和时间。在下一章中,我们会让国际用户更加高兴,我们让 microblog 支持多语言。
如果你想要节省时间的话,你可以下载 microblog-0.13.zip。
我希望能在下一章继续见到各位!
国际化和本地化¶
今天的文章的主题是国际化和本地化,通常简称 I18n 和 L10n。我们想要我们的 microblog 应用程序被尽可能多的用户使用,因为我们不能忘记有许多人是不是讲英文的,或者会说英文,但是更愿意讲本国语言。
为了使得我们的应用程序便于外国访问者,我们将要使用 Flask-Babel 扩展,它提供了一种简单使用的框架用来把应用程序翻译成不用的应用。
如果你还没有安装 Flask-Babel,现在是时候安装。对于 Linux 和 Mac 用户:
flask/bin/pip install flask-babel
对于 Windows 用户:
flask\Scripts\pip install flask-babel
配置¶
Flask-Babel 可以简单地通过创建 Babel 类的一个实例并且传入 Flask 应用对象给它来初始化(文件 app/__init__.py):
from flask.ext.babel import Babel
babel = Babel(app)
我们也需要决定我们将要提供翻译的语言种类。现在我们将要开始一个西班牙版本,因为我们有一个西语的翻译器在手上,以后添加其它语言的版本也是很容易的。支持语言的列表被添加到配置文件中(文件 config.py):
# -*- coding: utf-8 -*-
# ...
# available languages
LANGUAGES = {
'en': 'English',
'es': 'Español'
}
LANGUAGES 字典有可用语言代码的键,以及可打印的语言名称作为值。我们使用短的语言代码,但是要指明语言和地域的话,也可能使用长代码。比如,如果我们要支持美国和英国英语的话,我们的字典里面可以有 ‘en-US’ 和 ‘en-GB’。
注意因为 Español 有一个外来字符,我们必须在 Python 源代码文件顶部中添加 coding 声明,告诉 Python 解释器我们是使用 UTF-8 编码 不是 ASCII,因为 ASCII 编码缺少 ñ 字符。
接下来的一个配置就是我们需要一个 Babel 用于决定使用哪种语言的函数(文件 app/views.py):
from app import babel
from config import LANGUAGES
@babel.localeselector
def get_locale():
return request.accept_languages.best_match(LANGUAGES.keys())
这个函数有一个 localeselector 装饰器,它被调用在请求之前为了当产生响应的时候给我们机会选择使用的语言。现在为止我们做的是简单的,我们只要读取浏览器发送的 HTTP 请求中的 Accept-Languages 头并且从我们支持的语言列表中选择最匹配的语言。这个过程实际上也相当简单,best_match 方法为我们做了所有工作。
Accept-Languages 头在大多数浏览器上被默认配置成操作系统层的所选择的语言,但是所有的浏览器给我们机会选择其它的语言。用户可以提供语言列表,每一个都有权重。作为例子,下面是复杂的 Accept-Languages 头:
Accept-Language: da, en-gb;q=0.8, en;q=0.7
上面的头信息表示最佳的语言是丹麦语(默认权重为 1),接着是英国英语(权重是 0.8)以及最后一个选项是通用英语(权重是 0.7)。
最后一项配置是我们需要一个 Babel 配置文件,它告诉 Babel 在我们代码和模板中的哪里去寻找翻译的文本(文件 babel.cfg):
[python: **.py]
[jinja2: **/templates/**.html]
extensions=jinja2.ext.autoescape,jinja2.ext.with_
最前面的两行告诉 Babel 我们的 Python 代码以及模版的文件名模式。第三行是告诉 Babel 启用一些扩展使得它能够在 Jinja2 模版中寻找翻译的文本。
标记翻译文本¶
现在到了这个任务最繁琐的地方。我们需要检查所有的代码和模版标记所有需要翻译的英文文本以便 Babel 能够找到它们。例如,看看从 after_login 函数中代码片段:
if resp.email is None or resp.email == "":
flash('Invalid login. Please try again.')
redirect(url_for('login'))
这里有一个闪现消息需要翻译。为了使得 Babel 知道这个文本,只要把这个字符串传入到 gettext 函数:
from flask.ext.babel import gettext
# ...
if resp.email is None or resp.email == "":
flash(gettext('Invalid login. Please try again.'))
redirect(url_for('login'))
在模板中我们必须做一些类似的工作,但是我们使用 _() 来简化 gettext()。比如,在我们基础模版中的链接的文本 Home:
<li><a href="{{ url_for('index') }}">Home</a></li>
能够被标记翻译如下:
<li><a href="{{ url_for('index') }}">{{ _('Home') }}</a></li>
不幸地是,不是所有我们要翻译的文本像上面一样的简单。作为一个例子,考虑下来自我们的 post.html 子模板中的如下的片段:
<p><a href="{{url_for('user', nickname = post.author.nickname)}}">{{post.author.nickname}}</a> said {{momentjs(post.timestamp).fromNow()}}:</p>
这里我们要翻译的结构式:“<nickname> 说 <when>:”。一种尝试就是只标记翻译 “说”,因为我们不确定在这一句中姓名以及时间组合的次序在所有语言中是一样的。正确的办法是标记整个语句并且使用对姓名与时间使用占位符,这样翻译器会在必要的时候改变次序。更复的杂情况是,名称里面内嵌了一个超链接。
gettext 函数是支持使用 %(name)s 语法占位符,这也是我们最好的解决办法。下面是一个类似情况的占位符的例子:
gettext('Hello, %(name)s', name = user.nickname)
回到我们的例子,这里是怎样标记文本翻译:
{% autoescape false %}
<p>{{ _('%(nickname)s said %(when)s:', nickname = '<a href="%s">%s</a>' % (url_for('user', nickname = post.author.nickname), post.author.nickname), when = momentjs(post.timestamp).fromNow()) }}</p>
{% endautoescape %}
因为我们在 nickname 占位符上放入了 HTML,我们需要关闭自动转义。但是关闭自动转义是一个很冒险的行为,渲染用户的输入并且不进行转义是很不安全的。
赋值给 when 占位符的文本是安全的,因为它是我们的 momentjs() 封装函数生成的文本。但是 nickname 占位符的文本是来自我们 User 模型中的 nickname 字段,这是来自数据库中并且完全由用户输入。如果用户在这个字段中输入特定意义的 HTML 或者 Javascript 脚本,我们没有对这些进行转义,可能我们会执行这些代码,这也许是一个后门。我们不能允许这样的事情,因此我们需要避免这种情况。
最有效的解决方案就是对 nickname 字段中使用的字符进行严格的限制。我们开始创建一个函数转换一个无效的 nickname 成一个有效(文件 app/models.py):
import re
class User(db.Model):
#...
@staticmethod
def make_valid_nickname(nickname):
return re.sub('[^a-zA-Z0-9_\.]', '', nickname)
这里我们只是从 nickname 字段中移除非字母,数字,.,_ 的字符。
当一个用户在页面注册,我们从 OpenID 提供商接收到他或者她的 nickname,因此我们必须确保转换这个 nickname (文件 app/views.py):
@oid.after_login
def after_login(resp):
#...
nickname = User.make_valid_nickname(nickname)
nickname = User.make_unique_nickname(nickname)
user = User(nickname = nickname, email = resp.email, role = ROLE_USER)
#...
同样在编辑用户信息的表单中,那里可以修改 nickname,我们需要在那里加强验证不允许非法字符(文件 app/forms.py):
class EditForm(Form):
#...
def validate(self):
if not Form.validate(self):
return False
if self.nickname.data == self.original_nickname:
return True
if self.nickname.data != User.make_valid_nickname(self.nickname.data):
self.nickname.errors.append(gettext('This nickname has invalid characters. Please use letters, numbers, dots and underscores only.'))
return False
user = User.query.filter_by(nickname=self.nickname.data).first()
if user is not None:
self.nickname.errors.append(gettext('This nickname is already in use. Please choose another one.'))
return False
return True
提取文本翻译¶
这里我不会列举所有需要翻译的代码和模版。感兴趣的读者可以检查 这里。
因此让我们假设我们已经发现所有文本并且把它们放入了 gettext() 或者 _() 调用中。那现在要干什么了?
现在我们运行 pybabel 提取文本到单独的文件中:
flask/bin/pybabel extract -F babel.cfg -o messages.pot app
Windows 用户使用这个命令:
flask\Scripts\pybabel extract -F babel.cfg -o messages.pot app
pybabel extract 命令会读取给定的配置文件,接着扫描在给定参数(在我们的例子中为 app)目录下的所有的代码和模版,当它发现标记翻译的文本就会把它拷贝到 messages.pot 文件。
messages.pot 文件是一个模板文件,其中包含所有需要翻译的文本。这个文件是用来作为一种生成语言文件的模型。
生成一个语言目录¶
这个过程的下一步就是为一个新语言创建翻译。我们说过我们要做西班牙版本(语言代码为 es),因此这是添加西班牙语到我们应用程序的命令:
flask/bin/pybabel init -i messages.pot -d app/translations -l es
pybabel init 命令把 .pot 文件作为输入,生成一个新语言目录,以 -d 选项指定的目录为新语言的目录,以 -l 指定的语言为想要翻译成的语言类型。默认情况下,Babel 希望翻译的语言在与模版相同目录级别的 translations 文件夹中,因此我们把它们放在这里。
在你运行上述命令后,一个目录 app/translations/es 是创建了。在它里面有另一个名为 LC_MESSAGES 的目录,在它里面有一个 messages.po 文件。
下面就是翻译成西班牙语的截图:
一旦文本翻译完成并且保存成 messages.po 文件,还有另外一个来发布这些文本:
flask/bin/pybabel compile -d app/translations
pybabel compile 这一步会读取 .po 文件的内容并且会在相同的目录下生成一个名为 .mo 的编译的版本。这个文件以一种优化的格式包含了翻译的文本,应用程序可以更高效地使用它。
翻译已经准备好被使用了。为了验证它你可以修改浏览器上的语言设置让西班牙语为最佳语言,或者你可以直接修改 get_locale 函数(文件 app/views.py):
@babel.localeselector
def get_locale():
return "es" #request.accept_languages.best_match(LANGUAGES.keys())
更新翻译¶
如果 messages.po 文件不完整会发生些什么,比如某些文本忘记了翻译?不会发生什么异常,应用程序会运行的好好的,只是这些文本不会被翻译继续显示成英文。
如果在我们的代码或者模版中丢失了一些英文文本的话会发生些什么?任何没有放入 gettext() 或者 _() 的字符串都不会在翻译文件中,因此 Babel 不会感知这些,它们依然保持英文。一旦我们把丢失的文本添加进 gettext(),运行如下命令可以升级翻译文件:
flask/bin/pybabel extract -F babel.cfg -o messages.pot app
flask/bin/pybabel update -i messages.pot -d app/translations
extract 命令与前面用过的是一样的,它只是生成一个更新的 messages.pot 文件,文件里添加了新的文本。update 调用会把更新的文件加入到所有翻译的语言中。
一旦每一个语言文件夹的 messages.po 文件被更新了,我们可以运行 poedit 查看更新的文本,接着重复 pybabel compile 命令使得新的文本对应用程序可用。
翻译 moment.js¶
目前为止,代码以及模版中的文本都已经翻译成西班牙版本,可以运行应用程序看看。
但是此时我们会发现时间戳仍然是英语的。我们使用的渲染日期和时间的 moment.js 没有并通知到需要一个不同语言的版本。
从 moment.js 的 文档 我们发现 moment.js 有多语言版本可用。因此我们下载了西班牙语版本的 moment.js,并把它放在 static/js 文件夹中命名为 moment-es.min.js。我们将会按照这种方式,把不同语言的 moment.js 以 moment-<language>.min.js 形式存入 static/js 中,以便以后我们可以自动地选择正确的版本。
为了能够在模版中加载正确语言版本的 moment.js,我们需要把语言的代码加入到 Flask 全局变量,跟记录登录用户是相同的方式(文件 app/views.py):
@app.before_request
def before_request():
g.user = current_user
if g.user.is_authenticated():
g.user.last_seen = datetime.utcnow()
db.session.add(g.user)
db.session.commit()
g.search_form = SearchForm()
g.locale = get_locale()
接着需要在基础模版中修改引用 moment.js 的代码(文件 app/templates/base.html):
{% if g.locale != 'en' %}
<script src="/static/js/moment-{{g.locale}}.min.js"></script>
{% endif %}
惰性求值¶
当我们继续把玩着我们的西班牙语版本的应用程序,发现了一个问题。当我们登出并且尝试重新登录的时候,出现一个英语的闪现消息 “请登录后访问本页。” 。这是哪里的消息?我们并没有加入这个消息,它是 Flask-Login 扩展做的。
Flask-Login 允许用户配置这个消息,因此我们要充分利用不会改变消息只是翻译这一点。因此,我们进行第一次尝试(文件 app/__init__.py):
from flask.ext.babel import gettext
lm.login_message = gettext('Please log in to access this page.')
但是它并不工作。gettext 必须在请求的内容中使用才会产生翻译信息。如果我们在请求之外的地方使用,它不会翻译只会给我们英语版本的默认文本。
幸好,Flask-Babel 提供另外一个函数 lazy_gettext,它不会像 gettext() 和 _() 一样立即翻译,相反它会推迟翻译直到字符串实际上被使用的时候才会翻译。这个函数就可以应用到这里:
from flask.ext.babel import lazy_gettext
lm.login_message = lazy_gettext('Please log in to access this page.')
最后,当使用 lazy_gettext 的时候,pybabel extract 命令需要一个额外的 -k 的选项指明是 lazy_gettext 函数:
flask/bin/pybabel extract -F babel.cfg -k lazy_gettext -o messages.pot app
接下来的事情就跟上面更新翻译一样。依次 pybabel update,poedit,pybabel compile。
随着 Flask 0.10 的问世,用户会话被序列化成 JSON。这给传入给 flash() 的参数的惰性求值带来问题。闪现的消息是被写入到用户会话中,但是用于包裹惰性求值的对象是一个复杂的结构,不能够直接转换成 JSON。Flask 0.9 并不会把用户会话被序列化成 JSON,因此没有这个问题。Flask-Babel 并没有解决这个问题,因此我们必须从我们这一边考虑解决问题。(文件 app/__init__.py ):
from flask.json import JSONEncoder
class CustomJSONEncoder(JSONEncoder):
"""This class adds support for lazy translation texts to Flask's
JSON encoder. This is necessary when flashing translated texts."""
def default(self, obj):
from speaklater import is_lazy_string
if is_lazy_string(obj):
try:
return unicode(obj) # python 2
except NameError:
return str(obj) # python 3
return super(CustomJSONEncoder, self).default(obj)
app.json_encoder = CustomJSONEncoder
快捷方式¶
因为 pybabel 命令是又长又难记,我们可以编写一个快速的以及干净的小脚本来替代前面我们使用的命令。
第一个脚本就是添加语言到翻译目录(文件 tr_init.py):
#!flask/bin/python
import os
import sys
if sys.platform == 'wn32':
pybabel = 'flask\\Scripts\\pybabel'
else:
pybabel = 'flask/bin/pybabel'
if len(sys.argv) != 2:
print "usage: tr_init <language-code>"
sys.exit(1)
os.system(pybabel + ' extract -F babel.cfg -k lazy_gettext -o messages.pot app')
os.system(pybabel + ' init -i messages.pot -d app/translations -l ' + sys.argv[1])
os.unlink('messages.pot')
接着一个脚本就是更新语言目录(文件 tr_update.py):
#!flask/bin/python
import os
import sys
if sys.platform == 'wn32':
pybabel = 'flask\\Scripts\\pybabel'
else:
pybabel = 'flask/bin/pybabel'
os.system(pybabel + ' extract -F babel.cfg -k lazy_gettext -o messages.pot app')
os.system(pybabel + ' update -i messages.pot -d app/translations')
os.unlink('messages.pot')
最后,就是编译目录的脚本(文件 tr_compile.py):
#!flask/bin/python
import os
import sys
if sys.platform == 'wn32':
pybabel = 'flask\\Scripts\\pybabel'
else:
pybabel = 'flask/bin/pybabel'
os.system(pybabel + ' compile -d app/translations')
这些脚本会让工作变得更加简单些!
结束语¶
今天我们实现一个网页应用程序很容易忽略的东西。用户希望在本地语言下使用,因此必须让我们的应用程序支持多种语言。
在接下来的文章中,我们将看看可能是国际化和本地化最复杂的方面,就是用户产生的内容的实时自动翻译。我们将会利用这个机会给我们的应用程序添加些 Ajax 的魔力。
如果你想要节省时间的话,你可以下载 microblog-0.14.zip。
我希望能在下一章继续见到各位!
Ajax¶
这将是国际化和本地化的最后一篇文章,我们将会尽所能使得 microblog 应用程序对非英语用户可用和更加友好。
不知道大家平时有没有见过网站上有一个 “翻译” 的链接,点击后会把翻译后的内容在旁边显示给用户,这些链接触发一个实时自动翻译的内容。谷歌显示这个 “翻译” 链接是为了能够显示外国语言的搜索结果。Facebook 显示它为了能够翻译 blog 内容。今天我们将要添加同样的功能的 “翻译” 链接到我们的 microblog!
客户端 VS 服务器端¶
在传统的沿用至今的服务器端的模型中,有一个客户端(用户的浏览器)发送请求到我们的服务器上。一个请求能够简单地请求一个页面,像当你点击 “你的信息” 链接,或者它能够让我们执行一个动作,像当用户编辑他的或者她的用户信息并且点击提交的按钮。在这两种类型的请求中服务器通过发送一个新的网页到客户端,直接或通过发出一个重定向的请求来完成这次请求。客户端接着使用新页代替目前的页面。这个循环就会重复只要用户停留在我们的网页上。我们叫这种模式为服务器端,因为服务器做了所有的工作而客户端只是在它们收到页面的时候显示出来。
在客户端模式中,我们有一个网页浏览器,再次发送请求到服务器上。服务器会像服务器端模式一样回应一个网页,但是不是所有的页面数据都是 HTML,同样也有代码,典型的就是用 Javascript 编写的。一旦客户端接收到页面会把它显示出来并且会执行携带的代码。从此,你有一个活跃的客户端,可以做自己的工作,没有接触外面的服务器。在严格的客户端,整个应用程序被下载到客户端在初始页面请求中,然后应用程序运行在客户端上不会刷新页面,只有向服务器获取或存储数据。这种类型的应用称为 单页应用 或者 SPAs。
大多数应用是这两种模式的结合体。我们的 microblog 应用程序是一个完全的服务器端应用,但是现在我们想要添加些客户端行为。为了实现实时翻译用户的 blog 内容,客户端浏览器将会发送一个请求到服务器,但是服务器将会回应一个翻译文本而且不需要页面刷新。客户端将会动态地插入翻译到当前页面。这种技术叫做 Ajax,这是 Asynchronous Javascript and XML 的简称。
翻译用户生成内容¶
多亏了 Flask-Babel 我们现在比较好的支持了多语言。假设我们能找到愿意帮助我们的翻译器,我们可以在尽可能多的语言中发布我们的应用程序。
但是还有一个遗漏问题。因为有很多各种语言的用户使用系统,那么用户发布的 blog 内容的语言也是多种的。可能不是本语种的用户不知道内容的含义,如果我们能够提供一种自动翻译的服务这种会不会更好?
这是一个用 Ajax 服务来实现的理想的功能。我们的首页可以显示很多的 blog,它们中的一些可能是不同语言的。如果我们使用传统的服务器端模式来实现翻译的话,一个翻译的请求可能会让原始页面被新的只翻译了选择的 blog 的页面替换。在用户读完翻译后,我们必须点击回退键去获取 blog 列表。事实上请求一个翻译并不是需要更新全部的页面,这个功能让应用程序更好,因为翻译的文本是动态地插入到原始的文本下面,其他的内容不会发生变化。因此,今天我们将会实现我们的 Ajax 服务。
实现实时翻译需要几个步骤。首先,我们需要确定要翻译的文本的原语言类型。一旦我们知道原语言类型我们也就知道需不需要对一个给定的用户翻译,因为我们也知道这个用户选择的语言类型。当翻译被提供,用户希望看到它的时候,将会调用 Ajax 服务。最后一步就是客户端的 javascript 代码将会动态地把翻译文本插入到页面中。
确定 blog 语言¶
我们首先的问题就是确定 blog 撰写的语言。这不是一门精确的科学,它不会总是能够检测的语言的类型,所以我们只能尽最大努力去做。我们将会使用 guess-language Python 模块。因此,请安装这个模块。针对 Linux 和 Mac OS X 用户:
flask/bin/pip install guess-language
针对 Windows 用户:
flask\Scripts\pip install guess-language
有了这个模块,我们将会扫描每一篇 blog 的内容试着猜测它的语言种类。因为我们不想一遍一遍地扫描同一篇 blog,我们将会针对每一篇 blog 只做一次,当用户提交 blog 的时候就去扫描。我们将会把每一篇 blog 的语言种类存储在数据库中。
因此让我们开始在我们的 Post 表中添加一个 language 字段:
class Post(db.Model):
__searchable__ = ['body']
id = db.Column(db.Integer, primary_key = True)
body = db.Column(db.String(140))
timestamp = db.Column(db.DateTime)
user_id = db.Column(db.Integer, db.ForeignKey('user.id'))
language = db.Column(db.String(5))
每一次修改数据库,我们都需要做一次迁移:
$ ./db_migrate.py
New migration saved as microblog/db_repository/versions/005_migration.py
Current database version: 5
现在我们已经在数据库中有了存储 blog 内容语言类型的地方,因此让我们检测每一个 blog 语言种类:
from guess_language import guessLanguage
@app.route('/', methods = ['GET', 'POST'])
@app.route('/index', methods = ['GET', 'POST'])
@app.route('/index/<int:page>', methods = ['GET', 'POST'])
@login_required
def index(page = 1):
form = PostForm()
if form.validate_on_submit():
language = guessLanguage(form.post.data)
if language == 'UNKNOWN' or len(language) > 5:
language = ''
post = Post(body = form.post.data,
timestamp = datetime.utcnow(),
author = g.user,
language = language)
db.session.add(post)
db.session.commit()
flash(gettext('Your post is now live!'))
return redirect(url_for('index'))
posts = g.user.followed_posts().paginate(page, POSTS_PER_PAGE, False)
return render_template('index.html',
title = 'Home',
form = form,
posts = posts)
如果语言猜测不能工作或者返回一个非预期的结果,我们会在数据库中存储一个空的字符串。
显示 “翻译” 链接¶
接下来一步就是在 blog 旁边显示 “翻译” 链接(文件 app/templates/posts.html):
{% if post.language != None and post.language != '' and post.language != g.locale %}
<div><a href="#">{{ _('Translate') }}</a></div>
{% endif %}
这个链接需要我们添加一个新的翻译文本, “翻译”(‘Translate’) 是需要被包含在翻译文件里面,这里需要执行前面一章介绍的更新翻译文本的流程。
我们现在还不清楚如何触发这个翻译,因此现在链接不会做任何事情。
翻译服务¶
在我们的应用能够使用实时翻译之前,我们需要找到一个可用的服务。
现在有很多可用的翻译服务,但是很多是需要收费的。
两个主流的翻译服务是 Google Translate 和 Microsoft Translator。两者都是有偿服务,但微软提供的是免费的入门级的 API。在过去,谷歌提供了一个免费的翻译服务,但已不存在。这使我们很容易选择翻译服务。
使用 Microsoft Translator 服务¶
为了使用 Microsoft Translator,这里有一些流程需要完成:
- 应用的开发者需要在 Azure Marketplace 上注册 Microsoft Translator app。这里可以选择服务级别(免费的选项在最下面)。
- 接着开发者需要 注册应用。注册应用将会获得客户端 ID 以及客户端密钥代码,这些用于发送请求的一部分。
一旦注册部分完成,接下来处理请求翻译的步骤如下:
这听起来很复杂,因此如果不需要关注细节的话,这里有一个做了很多“脏”工作并且把文本翻译成别的语言的函数(文件 app/translate.py):
try:
import httplib # Python 2
except ImportError:
import http.client as httplib # Python 3
try:
from urllib import urlencode # Python 2
except ImportError:
from urllib.parse import urlencode # Python 3
import json
from flask.ext.babel import gettext
from config import MS_TRANSLATOR_CLIENT_ID, MS_TRANSLATOR_CLIENT_SECRET
def microsoft_translate(text, sourceLang, destLang):
if MS_TRANSLATOR_CLIENT_ID == "" or MS_TRANSLATOR_CLIENT_SECRET == "":
return gettext('Error: translation service not configured.')
try:
# get access token
params = urlencode({
'client_id': MS_TRANSLATOR_CLIENT_ID,
'client_secret': MS_TRANSLATOR_CLIENT_SECRET,
'scope': 'http://api.microsofttranslator.com',
'grant_type': 'client_credentials'})
conn = httplib.HTTPSConnection("datamarket.accesscontrol.windows.net")
conn.request("POST", "/v2/OAuth2-13", params)
response = json.loads (conn.getresponse().read())
token = response[u'access_token']
# translate
conn = httplib.HTTPConnection('api.microsofttranslator.com')
params = {'appId': 'Bearer ' + token,
'from': sourceLang,
'to': destLang,
'text': text.encode("utf-8")}
conn.request("GET", '/V2/Ajax.svc/Translate?' + urlencode(params))
response = json.loads("{\"response\":" + conn.getresponse().read().decode('utf-8') + "}")
return response["response"]
except:
return gettext('Error: Unexpected error.')
这个函数从我们的配置文件中导入了两个新值,id 和密钥代码(文件 config.py):
# microsoft translation service
MS_TRANSLATOR_CLIENT_ID = '' # enter your MS translator app id here
MS_TRANSLATOR_CLIENT_SECRET = '' # enter your MS translator app secret here
上面的 ID 和密钥代码是需要自己去申请,步骤上面已经讲了。即使你只希望测试应用程序,你也能免费地注册这项服务。
因为我们又添加了新的文本,这些也是需要翻译的,请重新运行 tr_update.py,poedit 和 tr_compile.py 来更新翻译的文件。
让我们翻译一些文本¶
因此我们该怎样使用翻译服务了?这实际上很简单。这是例子:
$ flask/bin/python
Python 2.6.8 (unknown, Jun 9 2012, 11:30:32)
>>> from app import translate
>>> translate.microsoft_translate('Hi, how are you today?', 'en', 'es')
u'¿Hola, cómo estás hoy?'
服务器上的 Ajax¶
现在我们可以在多种语言之间翻译文本,因此我们准备把这个功能整合到我们应用程序中。
当用户点击 blog 旁的 “翻译” 链接的时候,会有一个 Ajax 调用发送到我们服务器上。我们将看看这个调用是如何生产的, 现在让我们集中精力实现服务器端的 Ajax 调用。
服务器上的 Ajax 服务像一个常规的视图函数,不同的是不返回一个 HTML 页面或者重定向,它返回的是数据,典型的格式化成 XML 或者 JSON。因为 JSON 对 Javascript 比较友好,我们将使用这种格式(文件 app/views.py):
from flask import jsonify
from translate import microsoft_translate
@app.route('/translate', methods = ['POST'])
@login_required
def translate():
return jsonify({
'text': microsoft_translate(
request.form['text'],
request.form['sourceLang'],
request.form['destLang']) })
这里没有多少新内容。这个路由处理一个携带要翻译的文本以及原语言类型和要翻译的语言类型的 POST 请求。因为这是个 POST 请求,我们获取的是输入到 HTML 表单中的数据,请直接使用 request.form 字典。我们用这些数据调用我们的一个翻译函数,一旦我们获取翻译的文本就用 Flask 的 jsonify 函数把它转换成 JSON。客户端看到的这个请求响应的数据类似这个格式:
{ "text": "<translated text goes here>" }
客户端上的 Ajax¶
现在我们需要从网页浏览器上调用 Ajax 视图函数,因为我们需要回到 post.html 子模板来完成我们最后的工作。
首先我们需要在模版中加入一个有唯一 id 的 span 元素,以便我们在 DOM 中可以找到它并且替换成翻译的文本(文件 app/templates/post.html):
<p><strong><span id="post{{post.id}}">{{post.body}}</span></strong></p>
同样,我们需要给一个 “翻译” 链接一个唯一的 id,以保证一旦翻译显示我们能隐藏这个链接:
<div><span id="translation{{post.id}}"><a href="#">{{ _('Translate') }}</a></span></div>
为了做出一个漂亮的并且对用户友好的功能,我们将会加入一个动态的图片,开始的时候是隐藏的,仅仅出现当翻译服务运行在服务器上,同样也有唯一的 id:
<img id="loading{{post.id}}" style="display: none" src="/static/img/loading.gif">
目前我们有一个名为 post<id> 的元素,它包含要翻译的文本,还有一个名为 translation<id> 的元素,它包含一个 “翻译” 链接但是不久就会被翻译后的文本代替,也有一个 id 为 loading<id> 的图片,它将会在翻译服务工作的时候显示。
现在我们需要在 “链接” 链接点击的时候触发 Ajax。与直接从链接上触发调用相反,我们将会创建一个 Javascript 函数,这个函数做了所有工作,因为我们有一些事情在那里做并且不希望在每个模板中重复代码。让我们添加一个对这个函数的调用当 “翻译” 链接被点击的时候:
<a href="javascript:translate('{{post.language}}', '{{g.locale}}', '#post{{post.id}}', '#translation{{post.id}}', '#loading{{post.id}}');">{{ _('Translate') }}</a>
变量看起来有些多,但是函数调用很简单。假设有一篇 id 为 23,使用西班牙语写的 blog,用户想要翻译成英语。这个函数的调用如下:
translate('es', 'en', '#post23', '#translation23', '#loading23')
最后我们需要实现的 translate(),我们将不会在 post.html 子模板中编写这个函数,因为每一篇 blog 内容会有些重复。我们将会在基础模版中实现这个函数,下面就是这个函数(文件 app/templates/base.html):
<script>
function translate(sourceLang, destLang, sourceId, destId, loadingId) {
$(destId).hide();
$(loadingId).show();
$.post('/translate', {
text: $(sourceId).text(),
sourceLang: sourceLang,
destLang: destLang
}).done(function(translated) {
$(destId).text(translated['text'])
$(loadingId).hide();
$(destId).show();
}).fail(function() {
$(destId).text("{{ _('Error: Could not contact server.') }}");
$(loadingId).hide();
$(destId).show();
});
}
</script>
结束语¶
近来当使用 Flask-WhooshAlchemy 为全文搜索的时候,会有一些数据库的警告。在下一章的时候,我们针对这个问题来讲讲 Flask 应用程序的调试技术。
如果你想要节省时间的话,你可以下载 microblog-0.15.zip。
我希望能在下一章继续见到各位!
调试,测试以及优化¶
我们小型的 microblog 应用程序已经足够的完善了,因此是时候准备尽可能地清理不用的东西。近来,一个读者反映了一个奇怪的数据库问题,我们今天将会调试它。这也提醒我们不论我们是多小心以及测试我们应用程序多仔细,我们还是会遗漏一些 bug。用户是很擅长发现它们的!
不是仅仅修复此错误,然后忘记它,直到我们遇到另一个。我们会采取一些积极的措施,以更好地准备下一个。
在本章的第一部分,我们将会涉及到 调试,我将会展示一些我平时调试复杂问题的技巧。
接着我们想要看看如何衡量我们的测试策略的效果。我们想要清楚地知道我们的测试能够覆盖到应用程序的多少,有时候称之为 测试覆盖率。
最后,我们将会研究下许多应用程序遭受过的一类问题,性能糟糕。我们将会看到 调优 技术,并且发现我们应用程序中哪些部分最慢。
听起来不错吧?让我们开始吧!
Bug¶
这个问题是由本系列的一个读者发现,他实现了一个允许用户删除自己的 blog 的新函数后遇到这个问题。我们正式的 microblog 版本是没有这个功能的,因此我们快速的加上它,以便我们可以调试这个问题。
我们使用删除 blog 的视图函数如下(文件 app/views.py):
@app.route('/delete/<int:id>')
@login_required
def delete(id):
post = Post.query.get(id)
if post == None:
flash('Post not found.')
return redirect(url_for('index'))
if post.author.id != g.user.id:
flash('You cannot delete this post.')
return redirect(url_for('index'))
db.session.delete(post)
db.session.commit()
flash('Your post has been deleted.')
return redirect(url_for('index'))
为了调用这个函数,我们将会在模板中添加这个删除链接(文件 app/templates/post.html):
{% if post.author.id == g.user.id %}
<div><a href="{{ url_for('delete', id = post.id) }}">{{ _('Delete') }}</a></div>
{% endif %}
现在我们接着继续,在生产模式下运行我们的应用程序。Linux 和 Mac 用户可以这么做:
$ ./runp.py
Windows 用户这么做:
flask/Scripts/python runp.py
现在作为一个用户,撰写一篇 blog,接着改变主意删除它。当你点击删除链接的时候,错误出现了!
我们得到了一个简短的消息说,应用程序已经遇到了一个错误,并已通知管理员。其实这个消息就是我们的 500.html 模版。在生产模式下,当在处理请求的时候出现一个异常错误,Flask 会返回一个 500 错误模版给客户端。因为我们是处于生产模式下,我们看不到错误信息或者堆栈轨迹。
现场调试问题¶
回想 单元测试 这一章,我们开启了一些调试服务在应用程序中的生产模式版本。当时我们创造了一个写入到日志文件的日志记录器,以便应用程序可以在运行时写入调试或诊断信息。Flask 自身会在结束一个错误 500 代码请求之前写入不能处理的任何异常的堆栈轨迹。作为一个额外的选项,我们也开启了基于日志的邮件通知服务,它将会向管理员列表发送日志信息邮件当一个错误写入日志信息的时候。
因此像上面的 bug,我们能够从两个地方,日志文件和发送的邮件,获得捕获的调试信息。
一个堆栈轨迹并不足够,但是总比没有好吧。假设我们对问题一点都不知道,我们需要单从堆栈轨迹中之处发生些什么。这是这个特别的堆栈轨迹的副本:
127.0.0.1 - - [03/Mar/2013 23:57:39] "GET /delete/12 HTTP/1.1" 500 -
Traceback (most recent call last):
File "/home/microblog/flask/lib/python2.7/site-packages/flask/app.py", line 1701, in __call__
return self.wsgi_app(environ, start_response)
File "/home/microblog/flask/lib/python2.7/site-packages/flask/app.py", line 1689, in wsgi_app
response = self.make_response(self.handle_exception(e))
File "/home/microblog/flask/lib/python2.7/site-packages/flask/app.py", line 1687, in wsgi_app
response = self.full_dispatch_request()
File "/home/microblog/flask/lib/python2.7/site-packages/flask/app.py", line 1360, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/microblog/flask/lib/python2.7/site-packages/flask/app.py", line 1358, in full_dispatch_request
rv = self.dispatch_request()
File "/home/microblog/flask/lib/python2.7/site-packages/flask/app.py", line 1344, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/home/microblog/flask/lib/python2.7/site-packages/flask_login.py", line 496, in decorated_view
return fn(*args, **kwargs)
File "/home/microblog/app/views.py", line 195, in delete
db.session.delete(post)
File "/home/microblog/flask/lib/python2.7/site-packages/sqlalchemy/orm/scoping.py", line 114, in do
return getattr(self.registry(), name)(*args, **kwargs)
File "/home/microblog/flask/lib/python2.7/site-packages/sqlalchemy/orm/session.py", line 1400, in delete
self._attach(state)
File "/home/microblog/flask/lib/python2.7/site-packages/sqlalchemy/orm/session.py", line 1656, in _attach
state.session_id, self.hash_key))
InvalidRequestError: Object '<Post at 0xff35e7ac>' is already attached to session '1' (this is '3')
如果你习惯读别的语言的堆栈轨迹,请注意 Python 的堆栈轨迹是反序的,最下面的是引起异常的发生点。
从上面的堆栈轨迹中我们可以看到异常是被 SQLAlchemy 会话处理代码触发的。在堆栈轨迹中,对找出我们代码最后的执行语句也是十分有帮助的。我们会最后定位到我们的 app/views.py 文件中的 delete() 函数中的 db.session.delete(post) 语句。
我们从上面的情况中可以知道 SQLAlchemy 是不能在数据库会话中注册删除操作。但是我们不知道为什么。
如果你仔细看看堆栈轨迹的最下面,你会发现问题好像在 Post 对象最开始绑定在会话 ‘1’,现在我们试着绑定同一对象到会话 ‘3’ 中。
如果你搜索这个问题的话,你会发现很多用户都会遇到这个问题,尤其是使用一个多线程网页服务器,它们得到两个请求尝试同时把同一对象添加到不同的会话。但是我们使用的是 Python 开发网页服务器,它是一个单线程服务器,因此这不是我们问题的原因。这可能的原因是不知道什么操作导致两个会话在同一时间活跃。
如果我们想要了解更多的问题,我们应该尝试以一种更可控的环境下重现错误。幸运的是,在开发模式下的应用程序试图重现这个问题,它确实重现了。在开发模式中,当发生异常时,我们得到是 Flask web 的堆栈轨迹,而不是 500.html 模板。
web 的堆栈轨迹是十分好的,因为它允许你检查代码并且从服务器上计算表达式。没有真正理解在这段代码中到底为什么会发生这种事情,我们只是知道某些原因导致一个请求在结束的时候没有正常删除会话。因此更好的方案就是找出到底是谁创建这个会话。
使用 Python 调试器¶
最容易找出谁创建一个对象的方式就是在对象构建中设置断点。断点是一个当满足一定条件的时候中断程序的命令。此时此刻,这是能够检查程序,比如获取中断时的堆栈轨迹,检查或者甚至改变变量值,等等。断点是 调试器 的特色之一。这次我们将会使用 Python 内置模块,叫做 pdb。
但是我们该检查哪个类?让我们回到基于 Web 的堆栈轨迹,再仔细找找。在最底层的堆栈帧中,我们能使用代码浏览器和 Python 控制台来找出使用会话的类。在代码中,我们看到我们是在 Session 类中。这像是 SQLAlchemy 中的数据库会话的基础类。因为现在在最底层的堆栈帧正是在会话对象里,我们能够在控制台中得到会话实际的类,通过运行:
>>> print self
<flask_sqlalchemy._SignallingSession object at 0xff34914c>
现在我们知道使用中的会话是通过 Flask-SQLAlchemy 定义的,因此这个扩展可能定义自己的会话类,作为 SQLAlchemy 会话的一个子类。
现在我们可以到 Flask-SQLAlchemy 扩展的 flask/lib/python2.7/site-packages/flask_sqlalchemy.py 中检查源代码并且定位到类 _SignallingSession 和它的 __init__() 构造函数,现在我们准备用调试器工作。
有很多方式在 Python 应用程序中设置断点。最简单的一种就是在我们想要中断的程序中写入如下代码:
import pdb; pdb.set_trace()
因此我们继续向前并且暂时在 _SignallingSession 类的构造函数插入断点(文件 flask/lib/python2.7/site-packages/flask_sqlalchemy.py):
class _SignallingSession(Session):
def __init__(self, db, autocommit=False, autoflush=False, **options):
import pdb; pdb.set_trace() # <-- this is temporary!
self.app = db.get_app()
self._model_changes = {}
Session.__init__(self, autocommit=autocommit, autoflush=autoflush,
extension=db.session_extensions,
bind=db.engine,
binds=db.get_binds(self.app), **options)
# ...
让我们继续运行看看会发生什么:
$ ./run.py
> /home/microblog/flask/lib/python2.7/site-packages/flask_sqlalchemy.py(198)__init__()
-> self.app = db.get_app()
(Pdb)
因为没有打印出 “Running on ...” 的信息我们知道服务器实际上并没有完成启动过程。中断可能已经发生了在内部某些神秘的代码里面。
最重要的问题是我们需要回答应用程序现在处于哪里,因为这将会告诉我们谁在请求创建会话 ‘1’。我们将会使用 bt 来获取堆栈轨迹:
(Pdb) bt
/home/microblog/run.py(2)<module>()
-> from app import app
/home/microblog/app/__init__.py(44)<module>()
-> from app import views, models
/home/microblog/app/views.py(6)<module>()
-> from forms import LoginForm, EditForm, PostForm, SearchForm
/home/microblog/app/forms.py(4)<module>()
-> from app.models import User
/home/microblog/app/models.py(92)<module>()
-> whooshalchemy.whoosh_index(app, Post)
/home/microblog/flask/lib/python2.6/site-packages/flask_whooshalchemy.py(168)whoosh_index()
-> _create_index(app, model))
/home/microblog/flask/lib/python2.6/site-packages/flask_whooshalchemy.py(199)_create_index()
-> model.query = _QueryProxy(model.query, primary_key,
/home/microblog/flask/lib/python2.6/site-packages/flask_sqlalchemy.py(397)__get__()
-> return type.query_class(mapper, session=self.sa.session())
/home/microblog/flask/lib/python2.6/site-packages/sqlalchemy/orm/scoping.py(54)__call__()
-> return self.registry()
/home/microblog/flask/lib/python2.6/site-packages/sqlalchemy/util/_collections.py(852)__call__()
-> return self.registry.setdefault(key, self.createfunc())
> /home/microblog/flask/lib/python2.6/site-packages/flask_sqlalchemy.py(198)__init__()
-> self.app = db.get_app()
(Pdb)
像之前做的,我们会发现在 models.py 的 92 行中存在问题,那里是我们全文搜索引擎初始化的地方:
whooshalchemy.whoosh_index(app, Post)
奇怪,在这个阶段我们并没有做触发数据库会话创建的事情,这看起来好像是初始化 Flask-WhooshAlchemy 的行为,它创建了一个数据库会话。
这感觉就像这毕竟不是我们的错误,也许某种形式的交互在两个 Flask 扩展 SQLAlchemy 和 Whoosh 之间。我们能停留在这里并且寻求两个扩展的开发者的帮助。或者是我们继续调试看能不能找出问题的真正所在。我将会继续,如果大家不感兴趣的话,可以跳过下面的内容。
让我们多看这个堆栈轨迹一眼。我们调用了 whoosh_index(),它反过来调用了 _create_index()。在 _create_index() 中的一行代码是这样的:
model.query = _QueryProxy(model.query, primary_key,
searcher, model)
在这里的 model 的变量被设置成我们的 Post 类,我们在调用 whoosh_index() 的时候传入的 Post 类。考虑到这一点,这看起来像是 Flask-WhooshAlchemy 创建了一个 Post.query 封装,它把原始的 Post.query 作为参数,并且附加些其它的 Whoosh 特别的东西。接着是最让人感兴趣的一部分。根据上面的堆栈轨迹,下一个调用的函数是 __get__(),这是一个 Python 的 描述符。
__get__() 方法是用于实现描述符,它是一个与它们行为关联的属性而不只是一个值。每次被引用,描述符 __get__() 的函数被调用。函数被支持返回属性的值。在这行代码中唯一被提及的的属性就是 query,所以现在我们知道,这个看似简单的属性,我们已经在过去使用的生成我们的数据库查询不是一个真正的属性,而是一个描述符。
让我们继续往下看看接下来发生什么。在 __get__() 中的代码是这个:
return type.query_class(mapper, session=self.sa.session())
这是一个相当暴露一段代码。比如,User.query.get(id) 我们间接调用 __get__() 方法来提供查询对象,这里我们能够看到这个查询对象会暗暗地带来一个数据库会话。
当 Flask-WhooshAlchemy 使用 model.query 同样会触发一个会话,这个会话被创建和与查询对象关联。但是这个查询对象与运行在我们视图函数中的查询对象不一样,Flask-WhooshAlchemy 请求并不是短暂的。Flask-WhooshAlchemy 把这个查询对象传入作为自己的查询对象,并且存入到 model.query。由于没有 __set__() 方法对应,新的对象将被存储为一个属性。对于我们的 Post 类,这就意味着在 Flask-WhooshAlchemy 完成初始化,我们将会有名称相同的描述符和属性。根据优先级,在这种情况下,属性胜出。
这一切最重要的方面是,这段代码设置一个持久的属性,里面有我们的会话 ‘1’ 。即使应用程序处理的第一个请求将使用这个会话,然后忘掉它,会话不会消失,因为它仍然是引用由 Post.query 属性。这是我们的错误!
该错误是由于混淆(我认为)描述的类型而造成的。它们看起来像常规属性,所以人们往往就这样使用它们。Flask-WhooshAlchemy 开发者只是想创建一个增强的查询对象用来为 Whoosh 查询存储一些有用的状态,但是他们没有意识到引用一个模型的 query 属性不像看起来的一样,背后隐藏与一个启动数据库的会话的属性关联。
回归测试¶
既然现在已经清楚了发生问题的原因所在,我们是不是可以试着重现下问题,为修复问题做一些准备。如果不愿意这么做的话,那可能只能等到 Flask-WhooshAlchemy 的开发者们去修复,那如果修复版本要等到一年以后?我们是不是要一直等待着,或者直接取消删除这个功能。
因此为了准备修复这个问题,我们可以试着去重现这个问题,我们可以试着去创建针对这个问题的测试。为了创建这个测试,我们需要模拟两个请求,第一个请求就是查询一个 Post 对象,模拟我们请求数据为了在首先显示 blog。因为这是第一个会话,我们准备命名这个会话为 ‘1’。接着我们需要忘记这个会话创建一个新的会话,就像 Flask-SQLAlchemy 所做的。试着删除 Post 对象在第二个会话中,这时候应该会触发这个 bug:
def test_delete_post(self):
# create a user and a post
u = User(nickname = 'john', email = '[email protected]')
p = Post(body = 'test post', author = u, timestamp = datetime.utcnow())
db.session.add(u)
db.session.add(p)
db.session.commit()
# query the post and destroy the session
p = Post.query.get(1)
db.session.remove()
# delete the post using a new session
db.session = db.create_scoped_session()
db.session.delete(p)
db.session.commit()
现在当我们运行测试的时候失败会出现:
$ ./tests.py
.E....
======================================================================
ERROR: test_delete_post (__main__.TestCase)
----------------------------------------------------------------------
Traceback (most recent call last):
File "./tests.py", line 133, in test_delete_post
db.session.delete(p)
File "/home/microblog/flask/lib/python2.7/site-packages/sqlalchemy/orm/scoping.py", line 114, in do
return getattr(self.registry(), name)(*args, **kwargs)
File "/home/microblog/flask/lib/python2.7/site-packages/sqlalchemy/orm/session.py", line 1400, in delete
self._attach(state)
File "/home/microblog/flask/lib/python2.7/site-packages/sqlalchemy/orm/session.py", line 1656, in _attach
state.session_id, self.hash_key))
InvalidRequestError: Object '<Post at 0xff09b7ac>' is already attached to session '1' (this is '3')
----------------------------------------------------------------------
Ran 6 tests in 3.852s
FAILED (errors=1)
修复¶
为了解决这个问题,我们需要找到一种连接 Flask-WhooshAlchemy 查询对象到模型的替代方式。
Flask-SQLAlchemy 的文档上提到过有一个 model.query_class 属性包含了用于查询的类。这实际上是一个更干净的方式使得 Flask-SQLAlchemy 使用自定义的查询类而不是 Flask-WhooshAlchemy 所做的。如果我们配置 Flask-SQLAlchemy 来创建查询使用 Whoosh 启用查询类(它已经是 Flask-SQLAlchemy BaseQuery 的子类),接着我们应该得到跟以前一样的结果,但是没有 bug。
我们在 github 上创建了一个 Flask-WhooshAlchemy 项目的分支,那里我已经实现上面这些修改。如果你想要看这些改变的话,请访问 github diff,或者下载 修改的扩展 并且安装它在原始的 flask_whooshalchemy.py 文件所在地。
测试覆盖率¶
虽然我们已经有了测试应用程序的测试代码,但是我们并不知道我们的应用程序有多少地方被测试到。我们需要一个测试覆盖率的工具来检查一个应用程序,在执行这个工具后我们能得到一个我们的代码现在哪些地方被测试到的报告。
Python 有一个测试覆盖率的工具,我们称之为 coverage。让我们安装它:
flask/bin/pip install coverage
这个工具可以作为一个命令行使用或者可以放在脚本里面。我们现在可以先不用考虑如何启动它。
这有些改变我们需要加入到测试代码中为了生成一个覆盖率的报告(文件 tests.py):
from coverage import coverage
cov = coverage(branch = True, omit = ['flask/*', 'tests.py'])
cov.start()
# ...
if __name__ == '__main__':
try:
unittest.main()
except:
pass
cov.stop()
cov.save()
print "\n\nCoverage Report:\n"
cov.report()
print "HTML version: " + os.path.join(basedir, "tmp/coverage/index.html")
cov.html_report(directory = 'tmp/coverage')
cov.erase()
我们开始在脚本的最开始初始化 coverage 模块。branch = True 参数要求除了常规的覆盖率分析还需要做分支分析。omit 参数确保不会去获得我们安装在虚拟环境和测试框架自身的覆盖率报告,我们只做我们的应用程序代码的覆盖。
为了收集覆盖率统计我们只要调用 cov.start(),接着运行我们的单元测试。我们必须从我们的单元测试框架中捕获以及通过异常,如果脚本不结束的话是没有机会生成一个覆盖率报告。在我们从测试中回来后,我们将会用 cov.stop() 停止覆盖率统计,并且用 cov.save() 生成结果。最后,cov.report() 把结果输出到控制台,cov.html_report() 生成一个好看的 HTML 报告,cov.erase() 删除数据文件。
这是运行后的报告例子:
$ ./tests.py
.....F
======================================================================
FAIL: test_translation (__main__.TestCase)
----------------------------------------------------------------------
Traceback (most recent call last):
File "./tests.py", line 143, in test_translation
assert microsoft_translate(u'English', 'en', 'es') == u'Inglés'
AssertionError
----------------------------------------------------------------------
Ran 6 tests in 3.981s
FAILED (failures=1)
Coverage Report:
Name Stmts Miss Branch BrMiss Cover Missing
------------------------------------------------------------
app/__init__ 39 0 6 3 93%
app/decorators 6 2 0 0 67% 5-6
app/emails 14 6 0 0 57% 9, 12-15, 21
app/forms 30 14 8 8 42% 15-16, 19-30
app/models 63 8 10 1 88% 32, 37, 47, 50, 53, 56, 78, 90
app/momentjs 12 5 0 0 58% 5, 8, 11, 14, 17
app/translate 33 24 4 3 27% 10-36, 39-56
app/views 169 124 46 46 21% 16, 20, 24-30, 34-37, 41, 45-46, 53-67, 75-81, 88-109, 113-114, 120-125, 132-143, 149-164, 169-183, 188-198, 203-205, 210-211, 218
config 22 0 0 0 100%
------------------------------------------------------------
TOTAL 388 183 74 61 47%
HTML version: /home/microblog/tmp/coverage/index.html
从上面的报告上可以看到我们测试 47% 的应用程序。我们也从上面得到没有被测试执行的函数的列表,因此我们必须重新看看这些行,考虑下我们还能编写些哪些测试。
我们能看到 app/models.py 覆盖率是比较高(88%),因为我们的测试集中在我们的模型。app/views.py 覆盖率是比较低(21%)因为我们没有在测试代码中执行视图函数。
我们新增加些测试为了提高覆盖率:
def test_user(self):
# make valid nicknames
n = User.make_valid_nickname('John_123')
assert n == 'John_123'
n = User.make_valid_nickname('John_[123]\n')
assert n == 'John_123'
# create a user
u = User(nickname = 'john', email = '[email protected]')
db.session.add(u)
db.session.commit()
assert u.is_authenticated() == True
assert u.is_active() == True
assert u.is_anonymous() == False
assert u.id == int(u.get_id())
def test_make_unique_nickname(self):
# create a user and write it to the database
u = User(nickname = 'john', email = '[email protected]')
db.session.add(u)
db.session.commit()
nickname = User.make_unique_nickname('susan')
assert nickname == 'susan'
nickname = User.make_unique_nickname('john')
assert nickname != 'john'
#...
性能调优¶
下一个话题就是性能。有什么比用户等待很长时间加载页面更令人沮丧的。我们想要确保我们的应用程序的速度,我们需要一些标准或者尺寸来衡量和分析。
我们使用的技术称为 profiling。一个代码分析器监视正在运行的程序,很像覆盖工具,而是注意到不是行执行而是多少时间花在每个函数上。在分析阶段结束的时候会生成一个报告,里面列出了所有执行的函数以及每个函数执行了多久。对这个列表从最大到最小的时间排序是一个很好的注意,这样可以得出我们需要优化的地方。
Python 有一个称为 cProfile 的代码分析器。我们能够把这个分析器直接嵌入到我们的代码中,但我们做任何工作之前,搜索是否有人已经完成了集成工作是一个好注意。一个对 “Flask profiler” 的快速搜索得出 Flask 使用的 Werkzeug 模块有一个分析器的插件,我们将直接使用它。
为了启用 Werkzeug 分析器,我们能创建一个像 run.py 的另外一个启动脚本。让我们称它为 profile.py:
#!flask/bin/python
from werkzeug.contrib.profiler import ProfilerMiddleware
from app import app
app.config['PROFILE'] = True
app.wsgi_app = ProfilerMiddleware(app.wsgi_app, restrictions = [30])
app.run(debug = True)
一旦这个脚本运行,每一个请求将会显示分析器的摘要。这里就是其中一个例子:
--------------------------------------------------------------------------------
PATH: '/'
95477 function calls (89364 primitive calls) in 0.202 seconds
Ordered by: internal time, call count
List reduced from 1587 to 30 due to restriction <30>
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.061 0.061 0.061 0.061 {method 'commit' of 'sqlite3.Connection' objects}
1 0.013 0.013 0.018 0.018 flask/lib/python2.7/site-packages/sqlalchemy/dialects/sqlite/pysqlite.py:278(dbapi)
16807 0.006 0.000 0.006 0.000 {isinstance}
5053 0.006 0.000 0.012 0.000 flask/lib/python2.7/site-packages/jinja2/nodes.py:163(iter_child_nodes)
8746/8733 0.005 0.000 0.005 0.000 {getattr}
817 0.004 0.000 0.011 0.000 flask/lib/python2.7/site-packages/jinja2/lexer.py:548(tokeniter)
1 0.004 0.004 0.004 0.004 /usr/lib/python2.7/sqlite3/dbapi2.py:24(<module>)
4 0.004 0.001 0.015 0.004 {__import__}
1 0.004 0.004 0.009 0.009 flask/lib/python2.7/site-packages/sqlalchemy/dialects/sqlite/__init__.py:7(<module>)
1808/8 0.003 0.000 0.033 0.004 flask/lib/python2.7/site-packages/jinja2/visitor.py:34(visit)
9013 0.003 0.000 0.005 0.000 flask/lib/python2.7/site-packages/jinja2/nodes.py:147(iter_fields)
2822 0.003 0.000 0.003 0.000 {method 'match' of '_sre.SRE_Pattern' objects}
738 0.003 0.000 0.003 0.000 {method 'split' of 'str' objects}
1808 0.003 0.000 0.006 0.000 flask/lib/python2.7/site-packages/jinja2/visitor.py:26(get_visitor)
2862 0.003 0.000 0.003 0.000 {method 'append' of 'list' objects}
110/106 0.002 0.000 0.008 0.000 flask/lib/python2.7/site-packages/jinja2/parser.py:544(parse_primary)
11 0.002 0.000 0.002 0.000 {posix.stat}
5 0.002 0.000 0.010 0.002 flask/lib/python2.7/site-packages/sqlalchemy/engine/base.py:1549(_execute_clauseelement)
1 0.002 0.002 0.004 0.004 flask/lib/python2.7/site-packages/sqlalchemy/dialects/sqlite/base.py:124(<module>)
1229/36 0.002 0.000 0.008 0.000 flask/lib/python2.7/site-packages/jinja2/nodes.py:183(find_all)
416/4 0.002 0.000 0.006 0.002 flask/lib/python2.7/site-packages/jinja2/visitor.py:58(generic_visit)
101/10 0.002 0.000 0.003 0.000 flask/lib/python2.7/sre_compile.py:32(_compile)
15 0.002 0.000 0.003 0.000 flask/lib/python2.7/site-packages/sqlalchemy/schema.py:1094(_make_proxy)
8 0.002 0.000 0.002 0.000 {method 'execute' of 'sqlite3.Cursor' objects}
1 0.002 0.002 0.002 0.002 flask/lib/python2.7/encodings/base64_codec.py:8(<module>)
2 0.002 0.001 0.002 0.001 {method 'close' of 'sqlite3.Connection' objects}
1 0.001 0.001 0.001 0.001 flask/lib/python2.7/site-packages/sqlalchemy/dialects/sqlite/pysqlite.py:215(<module>)
2 0.001 0.001 0.002 0.001 flask/lib/python2.7/site-packages/wtforms/form.py:162(__call__)
980 0.001 0.000 0.001 0.000 {id}
936/127 0.001 0.000 0.008 0.000 flask/lib/python2.7/site-packages/jinja2/visitor.py:41(generic_visit)
--------------------------------------------------------------------------------
127.0.0.1 - - [09/Mar/2013 19:35:49] "GET / HTTP/1.1" 200 -
在这个报告中每一行的含义如下:
- ncalls : 这个函数被调用的次数。
- tottime : 在这个函数中所花费所有时间。
- percall : 是 tottime 除以 ncalls 的结果。
- cumtime : 花费在这个函数以及任何它调用的函数的时间。
- percall : cumtime 除以 ncalls。
- filename:lineno(function) : 函数名以及位置。
有趣的是我们的模板也是作为函数出现的。这是因为 Jinja2 的模板是被编译成 Python 代码。现在看来暂时我们的应用程序还不存在性能的瓶颈。
数据库性能¶
为了结束这篇,我们最后看看数据库性能。从上一部分内容中数据库的处理是在性能分析的报告中,因此我们只需要在数据库变得越来越慢的时候能够获得提醒。
Flask-SQLAlchemy 文档提到了 get_debug_queries 函数,它返回在请求执行期间所有的查询的列表。
这是一个很有用的信息。我们可以充分利用这个信息来得到提醒。为了充分利用这个功能,我们在配置文件中需要启动它(文件 config.py):
SQLALCHEMY_RECORD_QUERIES = True
我们需要设置一个阀值,超过这个值我们认为是一个慢的查询(文件 config.py):
# slow database query threshold (in seconds)
DATABASE_QUERY_TIMEOUT = 0.5
为了检查是否需要发送警告,我们需要在每一个请求结束的时候进行处理。在 Flask 中,我们只需要设置一个 after_request 函数(文件 app/views.py):
from flask.ext.sqlalchemy import get_debug_queries
from config import DATABASE_QUERY_TIMEOUT
@app.after_request
def after_request(response):
for query in get_debug_queries():
if query.duration >= DATABASE_QUERY_TIMEOUT:
app.logger.warning("SLOW QUERY: %s\nParameters: %s\nDuration: %fs\nContext: %s\n" % (query.statement, query.parameters, query.duration, query.context))
return response
结束语¶
本章到这里就算结束了,本来打算为这个系列再写关于部署的内容,但是由于官方的教程已经很详细了,这里不再啰嗦了。有需要请访问 部署选择。
如果你想要节省时间的话,你可以下载 microblog-0.16.zip。
本系列准备到这里就结束了,希望大家喜欢!